엑셀로 회원 관리하다가 DBMS를 제대로 공부하기 시작한 이유
인프런에서 김영한님 실전 데이터베이스 입문 강의를 듣기 시작했다. SW마에스트로 프로젝트 하면서 DB를 대충 쓰기만 하고 왜 이렇게 설계됐는지는 제대로 몰랐던 게 계속 걸렸다. INSERT, SELECT 정도는 손에 익었지만 누가 “근데 이건 왜 이렇게 동작해?”라고 물으면 제대로 답을 못 할 것 같았다.
강의 자료 폴더를 열어보니 섹션 1은 MySQL 설치 얘기라 이미 세팅이 끝난 나는 건너뛰고, 섹션 2 “데이터베이스 소개”부터 정리해본다. 실습 없이 개념만 다루는 섹션이라 가볍게 훑고 넘어갈 줄 알았는데, 막상 정리하면서 보니 앞으로 나올 모든 것의 “왜”가 여기 다 들어있었다. 여섯 꼭지를 하나씩 정리한다.
데이터와 정보는 다른 말이다
강의 초반에 나온 얘기인데 생각보다 곱씹을 게 많았다. 나는 그동안 “데이터”와 “정보”를 거의 같은 말로 썼었다. 근데 이 강의는 이 둘을 명확히 세 단계로 쪼갠다.
1
2
3
4
5
데이터 (영수증 더미)
→ 규칙에 맞춰 정리 →
구조화된 데이터 (날짜|항목|금액 표)
→ 계산·해석 →
정보 ("이번 달 커피값 63,000원")
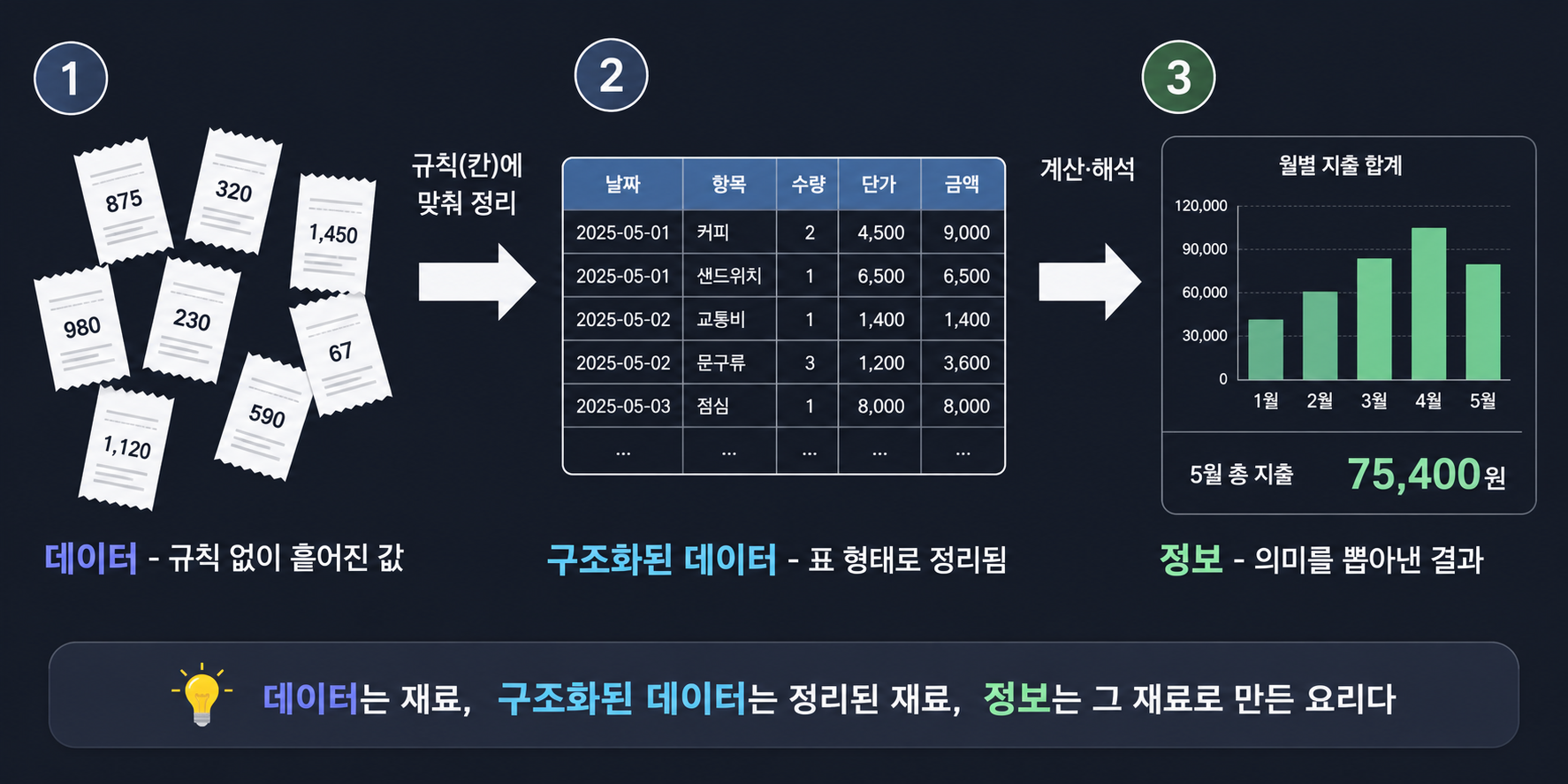
데이터 — 그냥 흩어진 값
영수증 뭉치를 서랍에 던져놓은 상태를 상상하면 된다. “커피 4500원” 영수증, “택시 12000원” 영수증이 각각 존재하긴 하는데, 순서도 규칙도 없다. 이 상태로 “이번 달 커피값 얼마 썼지?”라고 물으면 서랍을 뒤적거리면서 하나하나 찾아 더해야 한다. 데이터는 존재하지만 아무 쓸모도 없는 상태라는 게 이 강의의 표현이었다.
구조화된 데이터 — 규칙에 맞춰 정리한 것
| 영수증을 “날짜 | 항목 | 금액” 표로 옮겨 적으면 구조화된 데이터가 된다. 여기서부터는 어떤 값이 날짜고 어떤 값이 금액인지 컴퓨터도 구분할 수 있다. 그런데 여기서 중요한 게, 표로 정리했다고 바로 “커피값 얼마 썼는지”가 나오는 게 아니라는 거다. 나는 이 부분에서 “표만 만들면 끝 아닌가”라고 은근히 착각하고 있었다. |
정보 — 계산·해석까지 거친 결과
표에서 커피 항목만 골라 금액을 다 더해야 “63,000원”이라는 답이 나오고, 그게 정보다. SQL로 치면 SELECT SUM(금액) FROM 영수증 WHERE 항목 = '커피' 같은 쿼리가 이 “정보를 뽑아내는” 역할을 한다.
이 흐름은 실제 서비스에서도 그대로 보인다. 배달앱 사장님 통계 화면을 생각해보면, 주문 하나하나(데이터)가 날짜·메뉴별 테이블(구조화된 데이터)로 정리되고, 거기서 “화요일 저녁 매출이 가장 높다”(정보)는 통계가 나온다. 은행 앱도 마찬가지로 입출금 내역을 계좌 테이블로 정리한 다음 “이번 달 총 지출 128만원”처럼 가공해서 보여준다. 쇼핑몰도 클릭 로그(데이터)를 사용자별 주문 테이블(구조화된 데이터)로 정리한 뒤 “이 상품 재구매율 34%”(정보)로 분석한다고 한다.
나중에 어떤 컬럼을 만들지 설계할 때도 “이 데이터로 나중에 어떤 정보를 뽑아낼 건가”를 먼저 생각해야겠다는 생각이 들었다. 지금까지는 일단 컬럼부터 만들고 나중에 쿼리로 어떻게든 맞춰 쓰는 식이었는데, 순서가 거꾸로였던 것 같다.
파일시스템으로는 왜 안 되는가
DBMS가 왜 필요한지도 예전엔 “그냥 원래 쓰는 거니까” 정도로 넘어갔었는데, 이번엔 좀 더 구체적으로 이해됐다. 회원 정보를 엑셀 파일 하나로 관리한다고 치면 실제로 이런 문제가 생긴다.

데이터 중복과 종속성
같은 회원 정보가 주문마다 통째로 복사돼서 저장되는 게 데이터 중복이다. 회원이 이사를 가면 그 회원의 주문 100건을 다 찾아서 고쳐야 한다. 하나라도 빠뜨리면 같은 사람인데 주소가 다른, 앞뒤가 안 맞는 데이터가 생긴다.
“데이터 종속성”은 예시를 듣고 나서야 확실히 이해됐다. 옛날 방식은 파일의 각 줄이 “이름 10바이트 + 나이 3바이트 + 전화번호 11바이트” 순서로 고정돼 있고, 프로그램이 이 순서를 코드에 그대로 박아뒀다고 한다. 여기서 “이메일” 컬럼 하나만 추가해도 파일 구조가 바뀌니까, 그 파일을 읽는 프로그램(회원가입, 통계, 백업 프로그램 전부)을 찾아서 다시 고쳐야 한다는 거다.
DBMS를 쓰면 프로그램이 SELECT 이름, 전화번호 FROM 회원처럼 컬럼 이름으로 요청하기 때문에, 내부 저장 구조가 바뀌어도 기존 쿼리는 그대로 동작한다. 이걸 스키마 독립성이라고 부르는데, 정확히는 두 종류로 나뉜다.
- 논리적 독립성 — 테이블 구조(컬럼 추가 등)가 바뀌어도 기존 쿼리는 그대로 동작
- 물리적 독립성 — 내부 저장 방식(인덱스 추가 등)이 바뀌어도 테이블 구조와 쿼리는 그대로 유지
논리적 독립성이 물리적 독립성보다 지키기 어렵다고 한다. 테이블 구조를 바꾸는 건 그 테이블을 참조하는 여러 곳에 영향을 줄 가능성이 있어서, 실무에서는 컬럼을 삭제하는 대신 “안 쓰는 컬럼으로 남겨두기”나 “뷰(view)로 감싸기” 같은 방법을 쓴다고 한다. 이 부분은 나중에 실전에서 부딪혀봐야 체감이 될 것 같다.
동시 접근과 무결성 문제
“동시 접근 문제”는 예전에 팀 프로젝트에서 스프레드시트로 일정 관리하다가 실제로 겪어본 거라 바로 와닿았다. 두 명이 동시에 저장하면 나중에 저장한 사람 내용으로 통째로 덮어써졌던 그 짜증나던 순간이 딱 이거였다. 강의에서는 은행을 예로 들었는데, 초당 수천 건의 계좌 이체 요청이 동시에 들어와도 DBMS의 트랜잭션 제어 덕분에 잔액이 꼬이지 않는다고 한다. 우리가 겪었던 스프레드시트 사고가 은행 규모로 벌어지면 그야말로 대참사겠다 싶었다.
무결성 문제는 조금 더 단순한데, 파일에는 “이 칸에는 숫자만 들어가야 한다”거나 “이 값은 중복되면 안 된다” 같은 규칙을 강제할 방법이 없다는 거다. DBMS는 NOT NULL, UNIQUE, CHECK 같은 제약 조건으로 이걸 저장 시점에 막아준다.
보안과 장애 복구
파일 단위 접근 제어의 한계도 짚었다. 파일 하나를 통째로 숨길 수는 있어도, “이 컬럼만 특정 사용자에게 안 보이게” 하는 건 파일시스템으로는 불가능하다. DBMS는 사용자·권한별로 컬럼 단위까지 접근을 제어할 수 있다(GRANT/REVOKE).
장애 복구도 마찬가지다. 배달앱 정산 시스템이 파일이 아니라 DBMS에 저장돼 있으면, 정전이 나도 마지막 커밋 시점까지는 복구가 가능하다고 한다. 예전 같으면 “그냥 서버 죽으면 데이터도 날아가는 거 아닌가” 정도로 넘겼을 텐데, 이제는 그 뒤에 로그(WAL) 기반 복구라는 구체적인 메커니즘이 있다는 걸 알게 됐다.
DBMS와 데이터베이스는 다른 말이다
이것도 계속 섞어 쓰고 있었다. MySQL은 데이터베이스를 관리하는 소프트웨어(DBMS)고, 그 안에 실제로 들어있는 회원 정보 뭉치가 데이터베이스다. 도서관에 비유하면 DBMS는 “도서관 운영 시스템(사서, 대출 규칙, 서가 관리)” 전체고, 데이터베이스는 그 도서관 안에 있는 “책들의 모음” 그 자체다.
1
2
3
4
DBMS (MySQL)
└─ 데이터베이스 A (쇼핑몰 DB)
└─ 데이터베이스 B (사내 인사 DB)
└─ 데이터베이스 C (로그 DB)
CREATE DATABASE shop;, CREATE DATABASE hr; 이런 명령어가 전부 “DBMS에게 새로운 데이터베이스를 만들어달라”는 요청이라는 것도 이번에 정확히 짚었다. 하나의 DBMS 설치 안에 여러 개의 데이터베이스를 만들 수 있다는 걸 이번에 처음 명확히 알았다. 실무에서는 “DB”라는 말을 이 둘 다 섞어서 쓰니 문맥으로 구분해야 한다고 한다. “DB 서버 점검한다”는 DBMS(시스템 전체) 얘기고, “이 DB에 테이블 하나 추가한다”는 특정 데이터베이스 얘기인 경우가 많다.
클라이언트-서버로 동작한다는 것
그리고 DBMS가 클라이언트-서버 구조로 동작한다는 것도 이번에 처음 제대로 이해했다.
1
2
3
4
5
6
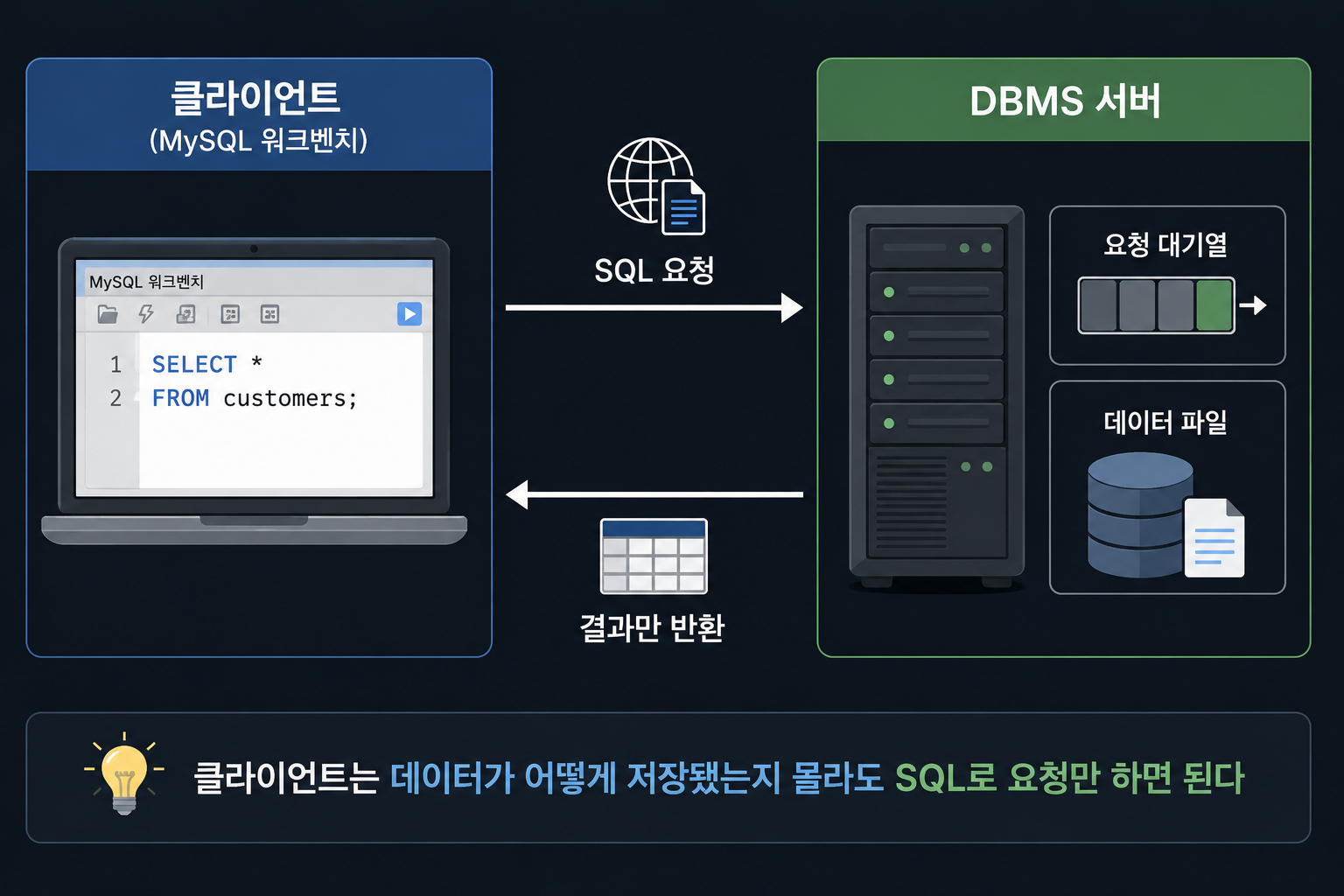
[클라이언트] [서버 = DBMS]
1. SQL 작성
SELECT * FROM customers → 2. 요청 수신, 처리 대기열에 등록
WHERE city = '서울'; 3. 실제 데이터 파일에서 조건에 맞는 행 검색
← 4. 결과(행·열 형태)만 네트워크로 전송
5. 결과를 화면에 표시
MySQL 워크벤치에서 SQL을 짜서 보내면(클라이언트), 서버가 요청을 받아서 처리 순서를 정하고, 실제 데이터를 찾아서 결과만 돌려준다. 식당에 비유하면 손님(클라이언트)이 종업원에게 주문만 하고, 주방(서버)이 실제로 요리해서 가져다주는 것과 같다. 손님은 주방이 어떻게 생겼는지 몰라도 되는 것처럼, 클라이언트도 데이터가 어떻게 저장돼 있는지 몰라도 된다.
왜 굳이 이렇게 클라이언트/서버로 분리했는지도 이해가 됐다. 모든 프로그램이 데이터 파일에 직접 접근하면 앞서 말한 “동시 접근 문제”가 그대로 재현되기 때문에, 서버 하나가 모든 요청을 중앙에서 순서대로 처리하는 거였다. 쇼핑몰로 치면 수만 명이 동시에 같은 상품 재고를 조회·주문해도, 서버가 중앙에서 순서를 정리해주니까 재고 수량이 꼬이지 않는 것과 같은 원리다.
나는 그동안 “내 컴퓨터에 설치했는데 왜 서버라는 말을 쓰지”라고 은근히 헷갈렸었는데, 클라이언트와 서버가 물리적으로 같은 컴퓨터 안에 있어도 논리적으로는 여전히 클라이언트-서버 구조라는 설명 듣고 정리됐다. 로컬 개발 환경에서 MySQL 서버 켜놓고 워크벤치로 접속하는 것도 결국 같은 구조라는 거다.
관계형 DB vs NoSQL, 그리고 실제로 쓰는 제품들
여기서부터는 강의 듣기 전부터 어렴풋이는 알고 있었지만, 트레이드오프를 명확히 짚어준 게 좋았다.
관계형 DB — 스키마를 먼저 정한다
관계형 DB는 표 구조(스키마)를 미리 정해두고 그 구조를 강제로 지키는 대신 정합성이 강하다.
1
2
3
4
5
6
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
dept VARCHAR(30),
hired_at DATE
);
이 스키마가 있으면 이름을 비워두고 저장하려고 하면 DBMS가 바로 거부한다(NOT NULL 위반). 인사팀 명부를 떠올리면 된다. “사번, 이름, 부서, 입사일” 양식이 한번 정해지면 모든 직원이 그 네 칸에 맞춰야 하고, 어떤 직원만 다섯 번째 칸을 특별히 갖는 건 안 된다.
NoSQL — 스키마를 미리 정하지 않는다
반면 NoSQL(예: MongoDB)은 스키마를 미리 정하지 않는다.
1
2
{ "name": "민준", "hobby": ["등산", "독서"] }
{ "name": "서연", "cert": ["정보처리기사"], "sns": "@seoyeon" }
두 번째 문서만 cert, sns 필드가 더 있어도 문제없이 저장된다. 관계형 DB였으면 스키마 위반으로 거부됐을 상황이다. 동호회 회원 명단처럼 사람마다 적고 싶은 정보가 완전히 다른 경우에 이 유연함이 빛을 발한다. 대신 NoSQL은 FOREIGN KEY 같은 강력한 무결성 검증 장치가 약해지고, 여러 문서에 걸친 복잡한 조회도 상대적으로 불편해진다.
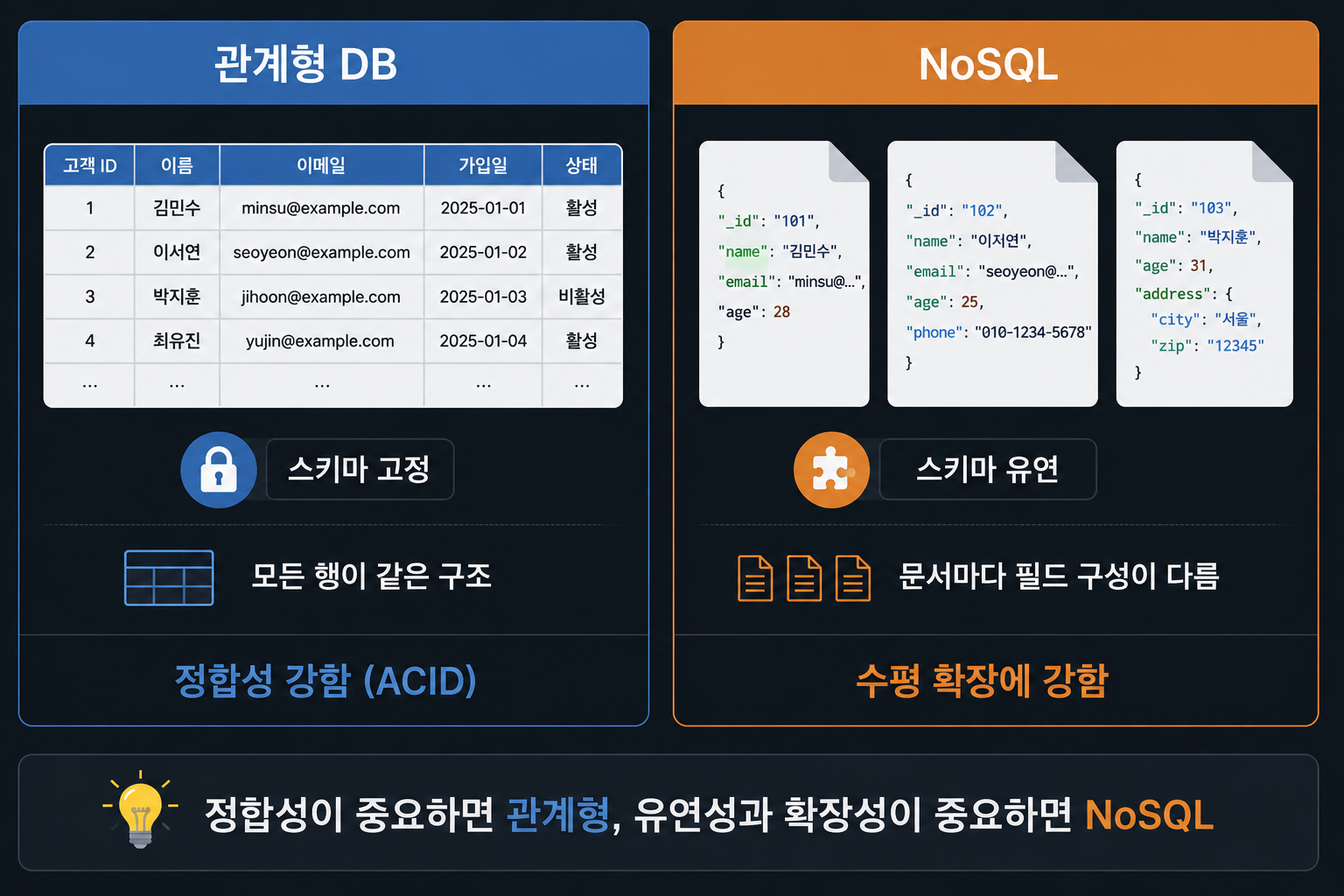
이 차이가 왜 실무에서 중요한지도 예시를 듣고 이해가 됐다. 은행이나 결제 시스템처럼 계좌 잔액같이 정합성이 생명인 데이터는 관계형 DB(트랜잭션, 무결성 제약)를 쓰고, 인스타그램 같은 SNS 피드처럼 게시글마다 첨부물 구성이 제각각인 데이터는 유연한 스키마의 NoSQL(MongoDB 등)을 쓴다고 한다. 실시간 랭킹이나 캐시처럼 빠른 읽기·쓰기가 중요한 경우엔 Redis 같은 키-값 NoSQL을 쓰기도 한다.
| 구분 | 관계형 DB | NoSQL |
|---|---|---|
| 스키마 | 미리 고정 | 유연/가변 |
| 일관성 | 강함(ACID) | 상대적으로 약함(BASE) |
| 확장 방식 | 수직 확장 중심 | 수평 확장(분산)에 강함 |
관계형 DB 제품들은 왜 여러 개인가
관계형 DB 안에서도 제품이 여러 개인 이유도 재밌었다. 자동차로 치면 세단, SUV, 경차가 다 “자동차”라는 큰 범주에 속하지만 가격과 용도가 다른 것과 같다.
| 제품 | 비용 | 강점 |
|---|---|---|
| MySQL | 무료 | 범용성, 큰 커뮤니티, 웹 서비스 표준 |
| Oracle DB | 유료(고가) | 수십 년간 검증된 안정성, 대규모 트랜잭션 |
| PostgreSQL | 무료 | 표준 SQL 준수도 높음, JSON·GIS 등 확장 기능 |
| MariaDB | 무료 | MySQL 개발자들이 만든 MySQL 호환 포크 |
MySQL은 무료라 네이버·카카오 계열 다수 서비스에서 초기 비용 부담 없이 빠르게 서비스를 시작할 때 많이 쓰고, Oracle은 비싸지만 대규모 트랜잭션 안정성 때문에 은행권 코어뱅킹 시스템처럼 수십 년간 검증된 안정성이 필요한 곳에서 여전히 많이 쓴다고 한다. MariaDB는 MySQL이 오라클(회사)에 인수된 뒤 원래 개발자들이 만든 MySQL 호환 포크라는 것도 이번에 처음 알았다.
표준 SQL을 다 같이 쓴다고는 하지만 제품마다 방언(dialect)이 있어서, 문자열을 합치는 것도 MySQL은 CONCAT(a, b)를 쓰는데 표준 SQL의 || 연산자는 MySQL 기본 설정에서 다르게 동작한다고 한다.
1
2
3
4
5
-- MySQL 방식
SELECT CONCAT(first_name, ' ', last_name) FROM members;
-- 표준 SQL 방식 (PostgreSQL 등에서 동작)
SELECT first_name || ' ' || last_name FROM members;
나중에 다른 DBMS로 옮길 일이 생기면 이 방언 차이부터 확인해야겠다. 이 강의는 MySQL 기준으로 진행되니 나도 MySQL로 계속 따라갈 예정이다.
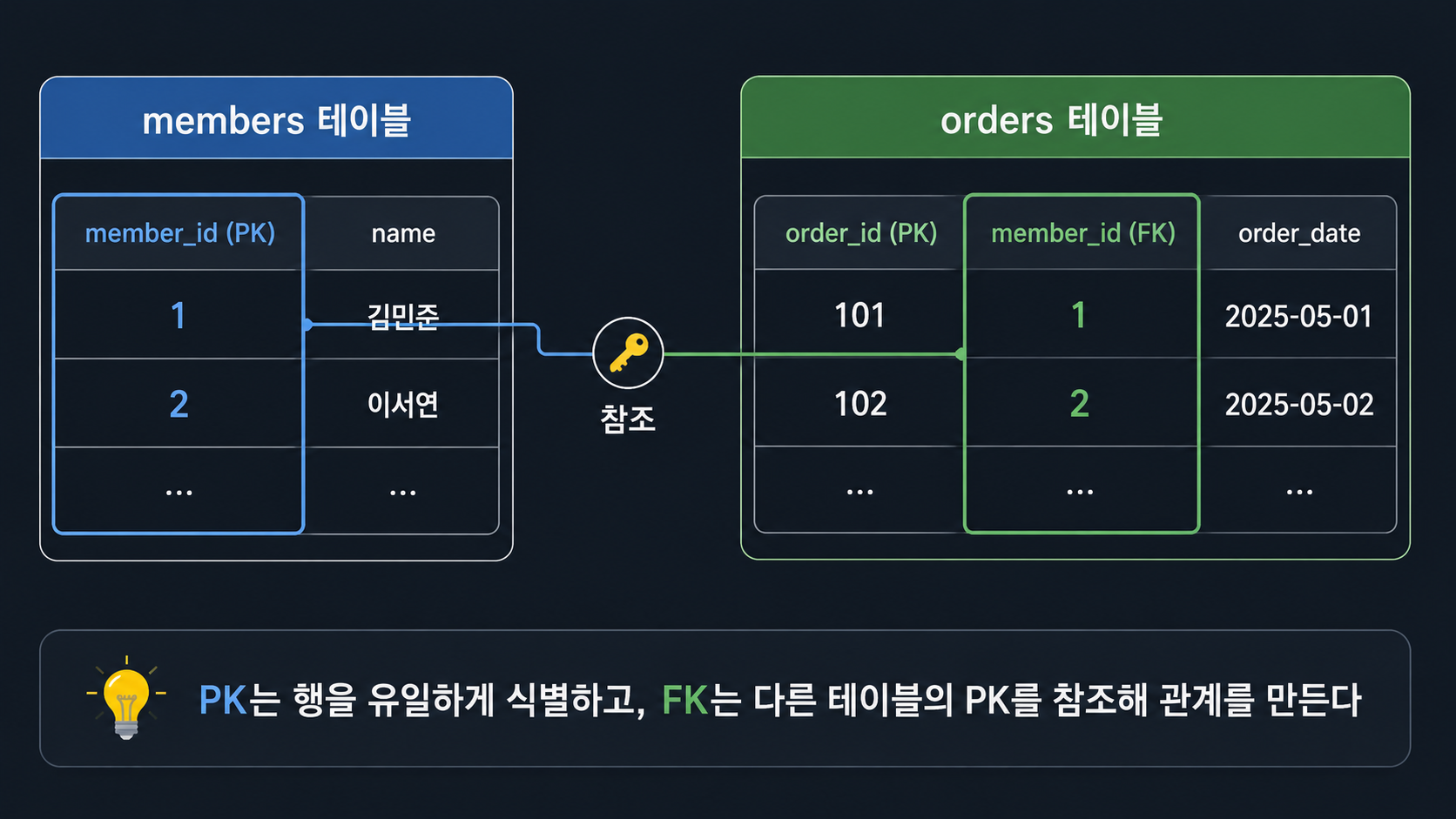
관계형 DB의 뼈대 — 테이블, PK, FK
섹션 2의 마지막은 관계형 DB를 실제로 구성하는 3요소였다.
테이블 — 데이터를 담는 그릇
학급 출석부를 떠올리면 된다. 세로 줄에는 “번호, 이름, 연락처”라는 항목(열, 컬럼)이 있고, 가로 줄마다 학생 한 명의 정보(행, 로우)가 채워져 있다. 관리하려는 대상(회원, 상품, 주문)마다 테이블을 하나씩 만든다.
1
2
3
4
5
CREATE TABLE members (
member_id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
phone VARCHAR(20)
);
PK(기본키) — 행을 유일하게 구분한다
학급에 “김민준”이 두 명 있으면 이름만으로는 누가 누군지 구분이 안 된다. 그래서 학교는 학번을 쓴다. 학번은 절대 겹치지 않으니까 “1201번 학생 나오세요”라고 하면 정확히 한 명만 나온다. PK가 바로 이 역할이다.
1
2
3
4
CREATE TABLE members (
member_id INT PRIMARY KEY, -- 기본키: 중복 불가, NULL 불가
name VARCHAR(50)
);
PK는 꼭 한 컬럼이어야 하는 건 아니다. 여러 컬럼을 조합해서 “이 조합이 유일하면 된다”고 정하는 복합키(composite key)도 있다. 예를 들어 수강신청 테이블이라면 “학번 + 과목코드” 조합이 PK가 될 수 있다. 같은 학생이 같은 과목을 두 번 신청할 수는 없으니까다.
FK(외래키) — 테이블끼리 관계를 맺는다
회사 출입증에 비유하면 이해가 쉬웠다. 출입증에는 사번만 적혀 있는데, 이 번호로 사원 명부를 조회하면 이름·부서·직급을 다 확인할 수 있다. 주문 테이블도 회원 이름을 통째로 적는 대신 회원의 고유 번호(FK)만 적어두는 거다.
1
2
3
4
5
6
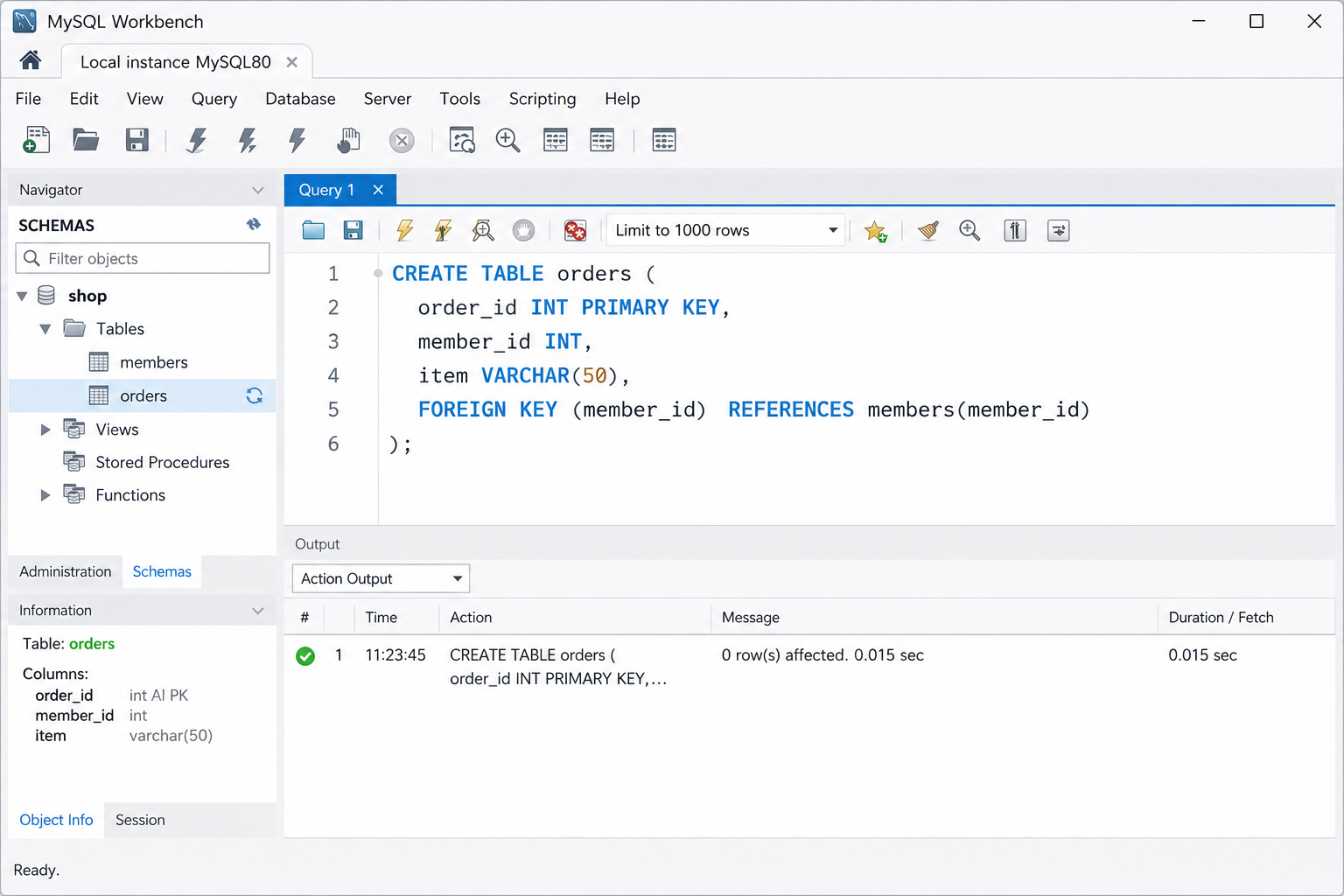
CREATE TABLE orders (
order_id INT PRIMARY KEY,
member_id INT, -- 이 컬럼이 외래키
item VARCHAR(50),
FOREIGN KEY (member_id) REFERENCES members(member_id)
);
1
2
3
4
[members] [orders]
member_id(PK) | name order_id(PK) | member_id(FK) | item
1 | 김민준 101 | 1 | 키보드
2 | 이서연 102 | 5 ← 거부! | (5번 회원 없음)
동명이인이 있어도 PK(member_id)로 구분하니까 절대 안 섞인다는 게 핵심이었다. 학사 시스템도 똑같은 원리로 동작한다고 한다. 학번(PK)을 수강신청·성적 테이블이 FK로 참조해서, 동명이인이 있어도 절대 안 섞이게 만든다. 은행도 계좌번호(PK)를 거래내역 테이블이 FK로 참조해서 어떤 거래가 어느 계좌 것인지 명확히 구분한다고 한다.
예전에 사이드 프로젝트에서 FK 없이 그냥 텍스트로 회원명을 주문 테이블에 박아넣었다가 오타 때문에 데이터가 꼬였던 기억이 있는데, 그때 PK/FK 개념을 제대로 알았으면 애초에 그런 실수를 안 했을 것 같다.
참조 무결성과 삭제 제약
존재하지 않는 회원 번호로 주문을 넣으려고 하면 DBMS가 아예 거부한다. 이걸 참조 무결성이라고 부른다. 참조당하는 쪽(members)의 행을 삭제하려고 하면 기본적으로 DBMS가 거부한다는 것도 짚었다. 그 회원을 참조하는 주문이 남아있으니까다. 삭제를 허용하려면 ON DELETE CASCADE 같은 옵션을 명시적으로 정해야 하는데, 이건 나중에 제약 조건 파트에서 더 자세히 다룬다고 하니 그때 따로 정리할 예정이다.
마무리
섹션 2를 정리하면서 느낀 건, 지금까지 관계형 DB를 쓰면서도 “왜 이렇게 설계됐는가”는 한 번도 제대로 생각해본 적이 없었다는 거다. 데이터→정보 흐름, 파일시스템의 한계, 클라이언트-서버 구조, 관계형 vs NoSQL의 트레이드오프, PK/FK의 존재 이유까지 전부 서로 연결된 하나의 이야기였다.
특히 스키마 독립성이랑 참조 무결성 부분은 그동안 “그냥 DBMS가 알아서 해주는 것” 정도로만 생각했었는데, 왜 그렇게 설계됐는지 이유를 알고 나니 앞으로 테이블을 설계할 때 좀 더 신중해질 것 같다. 다음 섹션은 실제로 MySQL 워크벤치를 켜서 CREATE DATABASE부터 시작한다고 하니, 그때부터는 직접 손으로 쳐보면서 배운 걸 코드로 남겨볼 예정이다.