화질을 숫자로 — VMAF와 FFmpeg 실전 트랜스코딩
코덱 시리즈를 쓰면서 계속 “CRF 23이면 화질이 괜찮다”, “preset을 slow로 하면 더 좋다” 같은 말을 감으로 써왔다. 그런데 정작 “괜찮다”는 게 뭘 기준으로 한 말인지 스스로도 애매했다.
이번에 화질을 숫자로 검증하는 법(VMAF·SSIM·PSNR)이랑, 그걸 실제 서비스에 적용하는 실전 트랜스코딩(하드웨어 인코딩, ABR 래더, HLS/DASH 패키징)까지 정리했다. 이걸로 코덱 시리즈도 마지막이다.
감으로 화질을 판단하던 문제
인코딩 설정을 바꿀 때마다 “이게 더 좋아진 건가?”를 눈으로만 확인하고 있었다. CRF를 23에서 20으로 낮췄을 때 화질이 좋아진 건 알겠는데, 정확히 얼마나 좋아졌는지, 그 대가로 파일이 얼마나 커졌는지를 숫자로 말할 수가 없었다.
더 큰 문제는 재현성이었다. 오늘 내 눈에 괜찮아 보인 화질이 내일도 똑같이 괜찮아 보일까? 다른 사람이 보면 다르게 느낄 수도 있다. 영상이 수백 개씩 쌓이는 서비스라면 사람이 일일이 재생해서 확인하는 것 자체가 불가능하다.
이 문제를 풀려고 나온 게 PSNR, SSIM, VMAF 같은 객관적 화질 측정 지표다.
PSNR — 가장 오래되고 가장 단순한 지표
PSNR(Peak Signal-to-Noise Ratio)은 통신 이론에서 신호와 잡음의 비율을 재던 방식을 영상에 그대로 가져온 지표다. 역사가 가장 오래됐고 계산이 단순하다.
계산 원리
원본 영상과 압축된 영상의 같은 위치 픽셀값을 하나씩 비교해서 차이를 구한다. 이 차이를 제곱해서 전체 픽셀에 대해 평균을 낸 게 MSE(Mean Squared Error, 평균제곱오차)다. 그리고 이 MSE를 로그 스케일로 변환해서 dB(데시벨) 단위로 표현한 게 PSNR이다.
1
2
3
4
5
6
1단계: MSE 계산
MSE = (1/N) × Σ(원본픽셀 - 압축픽셀)²
2단계: PSNR 변환
PSNR = 10 × log10(255² / MSE)
(255는 8비트 픽셀의 최댓값)
MSE가 작을수록(오차가 적을수록) PSNR 값은 커진다. 그래서 PSNR은 높을수록 좋은 화질이라는 뜻이다.
1
2
3
4
5
해석 기준:
PSNR 50dB+ → 거의 원본과 구분 불가
PSNR 40dB → 시각적으로 매우 좋음
PSNR 30dB → 눈에 띄는 손실 있지만 볼만함
PSNR 20dB- → 화질 저하가 뚜렷함
PSNR의 한계
문제는 PSNR이 “사람이 어떻게 느끼는지”를 전혀 고려하지 않는다는 점이다. 같은 PSNR 점수라도 체감 화질이 완전히 다를 수 있다.
1
2
3
4
5
영상 A: 화면 전체가 살짝 흐려짐 → PSNR 35dB
영상 B: 배경은 그대로, 얼굴만 뭉개짐 → PSNR 35dB (동일!)
사람이 보면: 영상 B가 훨씬 거슬린다 (얼굴은 시선이 집중되는 영역이니까)
PSNR은: 둘 다 똑같이 "괜찮다"고 판단
전체 화면에 균등하게 퍼진 손실과, 얼굴처럼 시선이 집중되는 영역에 몰린 손실을 PSNR은 구분하지 못한다. 픽셀 오차의 평균만 볼 뿐, 그 오차가 “어디에” 있는지는 신경 쓰지 않기 때문이다.

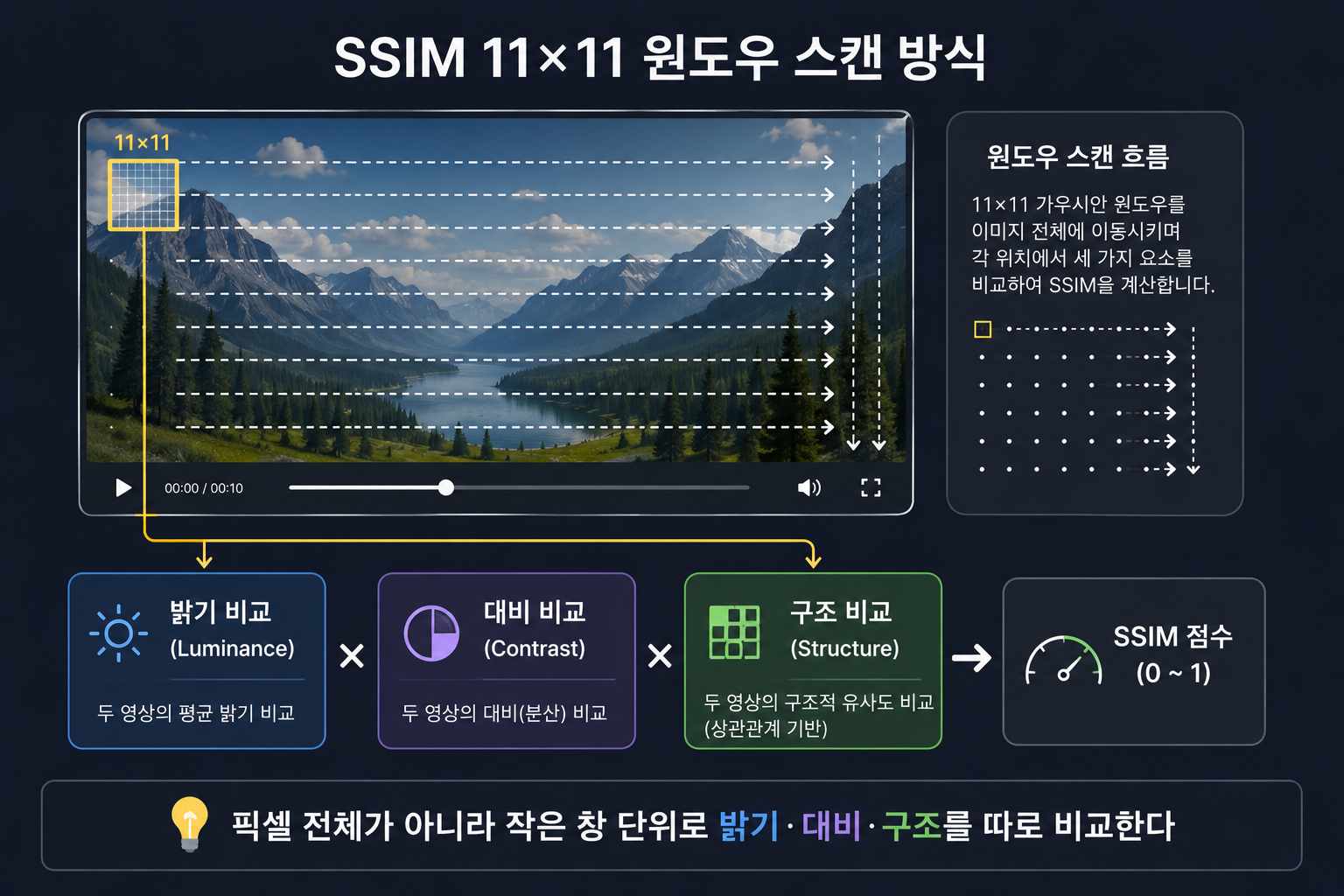
SSIM — 밝기·대비·구조를 따로 본다
PSNR의 한계를 보완하려고 2004년에 나온 지표가 SSIM(Structural Similarity Index)이다. 픽셀 전체를 한 번에 비교하지 않고, 작은 창(보통 11×11 픽셀짜리 가우시안 윈도우)을 영상 위에 스캔하듯 옮기면서 그 위치에서 세 가지를 따로 확인한다.
세 가지 비교 요소
1
2
3
4
5
SSIM(x, y) = l(x,y) × c(x,y) × s(x,y)
l(x,y) = 밝기 비교 (luminance)
c(x,y) = 대비 비교 (contrast)
s(x,y) = 구조 비교 (structure)
이 세 값을 곱해서 그 윈도우 위치의 점수를 내고, 영상 전체를 스캔하면서 이걸 평균 내면 최종 SSIM 점수(0~1)가 나온다. 1에 가까울수록 원본과 똑같다는 뜻이다.
SSIM이 PSNR과 결정적으로 다른 점은 “구조”에 큰 비중을 둔다는 것이다. 시각 과학 연구에 따르면 사람 눈은 화면이 전체적으로 살짝 밝아지거나 어두워지는 건 크게 신경 쓰지 않지만, 경계선이 흐트러지거나 패턴이 깨지는 왜곡에는 훨씬 민감하다. SSIM은 이 특성을 반영해서 설계됐다.
1
2
3
4
# FFmpeg으로 SSIM 계산
ffmpeg -i encoded.mp4 -i original.mp4 \
-lavfi ssim="stats_file=ssim.log" \
-f null -
SSIM도 완벽하진 않다
SSIM은 PSNR보다 사람 체감에 가깝지만, 여전히 하나의 고정된 수식이다 보니 모든 종류의 왜곡(블러, 블록 노이즈, 색 번짐, 모션 블러 등)을 다 잘 잡아내진 못한다. 특히 영상 특유의 시간적 흐름(프레임 간 움직임)은 SSIM 계산에 반영되지 않는다. 정지 이미지 비교 방식을 영상에 그대로 적용한 한계다.
VMAF — Netflix가 만든 종합 지표
PSNR과 SSIM 둘 다 “하나의 수식”으로 화질을 판단하려 했다. Netflix는 다르게 접근했다. 2016년에 내놓은 VMAF(Video Multimethod Assessment Fusion)는 “하나의 완벽한 공식을 찾지 말고, 여러 지표를 계산한 다음 실제 사람들이 매긴 점수로 학습시킨 모델에 넣어서 판단하자”는 아이디어다.
왜 Netflix가 이걸 만들었나
Netflix는 스트리밍 비용이 압도적으로 큰 회사다. 콘텐츠마다 최적의 비트레이트를 찾아야 하는데, 화질 판단을 정확히 할수록 “필요 이상으로 비트레이트를 쓰지 않으면서도 화질을 지키는” 최적화가 가능해진다. 그래서 사람 체감과 최대한 가까운 지표가 절실했다.
VMAF 계산 파이프라인
1
2
3
4
5
6
7
8
9
10
11
원본 영상 + 압축 영상
↓
[1] 여러 기초 지표 계산 (feature extraction)
- VIF (Visual Information Fidelity, 시각 정보 손실 정도)
- DLM (Detail Loss Measure, 디테일 손실 정도)
- 모션 정보 (프레임 간 움직임 정도)
↓
[2] SVM(Support Vector Machine) 회귀 모델에 입력
- 이 모델은 사전에 사람들이 실제로 매긴 주관 평가 점수(MOS)로 학습됨
↓
[3] 최종 VMAF 점수 출력 (0~100)
VIF나 DLM 같은 기초 지표 각각은 PSNR·SSIM처럼 특정 종류의 왜곡만 잘 잡아낸다. 그런데 이걸 여러 개 계산해서 머신러닝 모델에 넣으면, 모델이 “이 상황에서는 이 지표를 더 신뢰해야 한다”는 걸 데이터로 학습한다. 심사위원 한 명의 판단이 아니라 여러 심사위원의 의견을 종합하는 셈이다.
1
2
3
4
5
해석 기준:
VMAF 93+ → 사실상 무손실 수준 (Netflix 프리미엄 기준)
VMAF 80~93 → 좋은 화질, 스트리밍 배포 적당
VMAF 60~80 → 눈에 띄는 손실, 저용량 배포용
VMAF 60- → 화질 저하 뚜렷
VMAF는 모델 자체가 버전을 갖는다. vmaf_v0.6.1처럼 특정 학습 데이터로 만들어진 모델을 가리키고, 4K나 모바일 화면처럼 시청 환경이 다르면 그에 맞는 별도 모델을 쓰기도 한다.

실제로 세 지표를 뽑아보기
이론은 이해했는데 실제로 FFmpeg에서 어떻게 계산하는지가 중요하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# PSNR 계산
ffmpeg -i encoded.mp4 -i original.mp4 \
-lavfi psnr="stats_file=psnr.log" \
-f null -
# SSIM 계산
ffmpeg -i encoded.mp4 -i original.mp4 \
-lavfi ssim="stats_file=ssim.log" \
-f null -
# VMAF 계산 (libvmaf가 빌드에 포함돼 있어야 함)
ffmpeg -i encoded.mp4 -i original.mp4 \
-lavfi libvmaf="log_path=vmaf.json:log_fmt=json" \
-f null -
-i encoded.mp4 -i original.mp4에서 순서가 중요하다. libvmaf 필터 기준으로는 첫 번째가 압축본(distorted), 두 번째가 원본(reference)이다. -f null -은 실제 영상 파일을 출력하지 않고 필터 계산만 수행한다는 뜻이다. 점수만 필요할 뿐 인코딩 결과물이 필요한 게 아니라서다.
CRF 값을 바꿔가며 최적점을 찾는 스크립트를 짜면 이렇다.
1
2
3
4
5
6
7
8
9
10
11
12
#!/bin/bash
# CRF 18, 23, 28로 각각 인코딩 후 VMAF 비교
for crf in 18 23 28; do
ffmpeg -i original.mp4 -c:v libx264 -crf $crf -preset medium output_crf${crf}.mp4
ffmpeg -i output_crf${crf}.mp4 -i original.mp4 \
-lavfi libvmaf="log_path=vmaf_crf${crf}.json:log_fmt=json" \
-f null -
echo "CRF ${crf} 결과:"
cat vmaf_crf${crf}.json | grep -o '"mean":[0-9.]*' | head -1
done
grep -o '"mean":[0-9.]*'으로 VMAF json 결과에서 전체 프레임 평균 점수만 뽑아낸다. 목표 VMAF 점수(예: 95점 이상)를 만족하는 최소 CRF를 찾는 방식으로 이 루프를 실무에서 쓴다.
삽질 — libvmaf 필터가 없다는 에러
명령어를 그대로 쳤는데 “Unknown filter ‘libvmaf’“라는 에러가 떴다. FFmpeg을 설치하긴 했는데, 받은 FFmpeg 빌드에 VMAF 기능이 아예 빠져 있었던 거다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 진단: 현재 ffmpeg에 libvmaf가 포함돼 있는지 확인
ffmpeg -filters | grep vmaf
# 아무것도 안 나오면 libvmaf 없이 빌드된 것
# macOS 해결
brew install ffmpeg
# 최신 Homebrew ffmpeg은 기본적으로 libvmaf 포함
# Ubuntu 해결 (기본 apt 버전엔 libvmaf가 없는 경우가 많음)
sudo snap install ffmpeg
# 확인
ffmpeg -filters | grep vmaf
추정(FFmpeg 빌드 문제일 것) → 소거(-filters 옵션으로 실제 포함 여부 확인) → 검증(재설치 후 재확인) 순서로 접근하니 금방 원인을 찾았다. 이걸 겪고 나서는 새 서버에 FFmpeg 세팅할 때 -filters | grep vmaf부터 확인하는 습관이 생겼다.
삽질 — PSNR은 높은데 VMAF는 낮게 나오는 경우
CRF를 낮춰서 인코딩했는데 PSNR은 42dB로 꽤 높게 나왔다. 근데 VMAF는 75점밖에 안 됐다. 왜 두 지표가 다른 결과를 줬을까 헷갈렸다.
1
2
3
4
5
6
7
8
9
10
11
원인 후보:
1. 영상에 빠른 모션(카메라 팬, 스포츠 경기)이 있는 경우
→ PSNR은 픽셀 단위 오차만 보고, 모션 블러를 나쁘게 안 봄
→ VMAF는 모션 정보를 반영해서 프레임 간 흔들림에 더 민감
2. 화면 특정 영역(얼굴, 텍스트)에 왜곡이 몰린 경우
→ PSNR은 화면 전체 평균이라 부분 왜곡이 희석됨
→ VMAF의 디테일 손실 지표가 국소적 왜곡을 더 잘 감지
해결 방향:
→ PSNR 하나만 믿지 말고 VMAF를 최종 기준으로 삼는다
이후로는 PSNR을 1차 필터링용 정도로만 쓰고, 최종 판단은 VMAF로 하고 있다.
이제 실전 — FFmpeg으로 서비스에 적용하기
화질을 검증하는 법까지 배웠으니, 이걸 실제 서비스 트랜스코딩 파이프라인에 어떻게 적용하는지가 남았다. 여기서부터는 세 가지가 필요하다. 속도를 확보하는 하드웨어 인코딩, 여러 화질을 동시에 준비하는 ABR 래더, 그리고 이걸 실제 스트리밍 포맷으로 패키징하는 HLS/DASH다.
왜 CPU만으로는 안 됐나
CPU로 1080p 영상 하나를 인코딩하면 원본 재생시간과 비슷하거나 더 긴 시간이 걸린다. 그런데 화질별로 4개(360p, 480p, 720p, 1080p)를 다 만들어야 하면 단순 계산으로 4배 시간이 든다. 영상이 하루에 수천 개씩 올라오는 서비스라면 서버를 아무리 늘려도 감당이 안 되는 상황이 온다.
그리고 사용자마다 네트워크 환경이 다르다. 화질 하나만 준비해서 배포하면 느린 네트워크의 사용자는 계속 버퍼링에 시달리고, 빠른 네트워크의 사용자는 화질이 아까운 상황이 된다.
하드웨어 인코딩 — GPU의 전용 회로로 속도 확보
소프트웨어 vs 하드웨어 인코딩
libx264/libx265 같은 소프트웨어 인코더는 CPU의 범용 연산 능력으로 가능한 모든 경우의 수를 탐색해서 압축 효율을 최대화한다. 시간이 걸리더라도 최고의 결과를 뽑는 게 목표다.
Nvidia의 NVENC나 Intel의 QSV(Quick Sync Video)는 다르다. 인코딩에 자주 쓰이는 계산 패턴을 아예 전용 회로로 GPU나 내장 그래픽에 박아뒀다. 범용 계산보다 훨씬 빠르지만, CPU만큼 모든 경우의 수를 다 탐색하지는 못해서 압축 효율은 조금 떨어진다.
1
2
3
4
5
6
7
소프트웨어 인코딩 (libx264/libx265):
얻은 것: 같은 화질에서 파일 크기가 가장 작음
포기한 것: 속도
하드웨어 인코딩 (NVENC/QSV):
얻은 것: 속도 — 소프트웨어 대비 5~10배 이상 빠름
포기한 것: 압축 효율 — 같은 화질을 내려면 비트레이트를 좀 더 써야 함
실전 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 소프트웨어 인코딩 (CPU, libx264) — 압축 효율 최고
ffmpeg -i input.mp4 \
-c:v libx264 -crf 23 -preset slow \
output_sw.mp4
# 하드웨어 인코딩 (Nvidia GPU, NVENC)
ffmpeg -i input.mp4 \
-c:v h264_nvenc \
-preset p5 \ # NVENC 전용 preset (p1=빠름 ~ p7=고품질)
-cq 23 \ # NVENC의 CRF에 해당하는 품질 옵션
output_hw_nvidia.mp4
# 하드웨어 인코딩 (Intel Quick Sync)
ffmpeg -i input.mp4 \
-c:v h264_qsv \
-global_quality 23 \
output_hw_intel.mp4
NVENC는 자체적인 preset 체계(p1~p7)를 쓴다. libx264의 preset과 이름은 비슷하지만 완전히 다른 옵션이라 헷갈리지 않게 주의해야 한다. -cq도 CRF와 유사한 역할이지만 화질 스케일이 정확히 일치하지 않아서, 같은 숫자를 써도 체감 화질이 다를 수 있다. 이때 앞서 배운 VMAF로 실제 비교하는 게 정확하다.

삽질 — NVENC로 바꿨더니 화질이 나빠졌다
CPU 인코딩에서 CRF 23으로 잘 쓰던 설정을 그대로 NVENC의 -cq 23으로 바꿨는데, 결과물 화질이 확실히 나빠 보였다. 같은 숫자 23인데 왜 다를까 싶었다.
1
2
3
4
5
6
7
8
9
10
11
원인: NVENC의 CQ 스케일은 libx264 CRF와 정확히 매핑되지 않는다
+ NVENC 기본 preset이 낮은 품질(p1~p3 등)로 설정된 경우가 흔함
해결:
ffmpeg -i input.mp4 \
-c:v h264_nvenc \
-preset p6 \
-rc vbr_hq \ # 하드웨어 인코더의 고품질 VBR 모드
-cq 23 \
-b:v 0 \ # VBR 모드에서는 -b:v 0으로 CQ 우선 적용
output.mp4
preset을 고품질(p6, p7)로 바꾸고 rate-control 모드를 vbr_hq로 지정한 다음, VMAF로 실제 CPU 결과와 비교해서 검증했다. 숫자만 믿지 말고 직접 재보는 게 확실했다.
삽질 — GPU 인코딩 세션 제한
서버에서 동시에 여러 영상을 트랜스코딩하려는데, 몇 개 이상 돌리면 “session limit reached” 에러가 났다.
1
2
3
4
5
6
7
8
9
원인: 일반 소비자용 Nvidia GPU(GeForce)는 동시 NVENC 세션이 보통 3개로 제한됨
(하드웨어 스펙 제한이 아니라 드라이버 자체의 라이선스 제한)
확인:
nvidia-smi
해결 방향:
1. 데이터센터용 GPU(Tesla, A 시리즈)로 전환 — 세션 제한 없음/훨씬 높음
2. 여러 대의 저가 GPU를 분산 배치해서 세션을 나눠 처리
소규모 서비스가 GeForce로 트랜스코딩 서버를 구축했다가 트래픽이 늘면서 흔히 겪는 문제라고 한다. 처음부터 동시 처리량을 고려해서 데이터센터용 GPU나 클라우드 관리형 서비스(AWS MediaConvert 등)를 검토하는 게 나았다.
ABR 래더 — 화질별 사다리 설계
왜 여러 화질을 준비하나
화질을 하나로 통일하면 관리는 편하지만, 느린 네트워크 사용자는 계속 멈추고 빠른 네트워크 사용자는 화질이 아깝다. 그래서 여러 화질(ABR, Adaptive Bitrate)을 미리 준비해두고, 플레이어가 실시간으로 네트워크 속도를 측정해서 적절한 화질을 자동으로 고르게 한다.
여러 화질을 준비하면 인코딩 비용과 저장 공간이 늘어난다. 화질 4단계를 준비하면 저장 공간도 대략 4배 가까이 필요하다. 그런데 이 비용을 감수하는 이유는 스트리밍 서비스에서 재생 실패(버퍼링, 끊김)로 인한 이탈률이 가장 치명적인 지표이기 때문이다. 화질보다 매끄러운 재생을 우선하는 설계 철학이다.
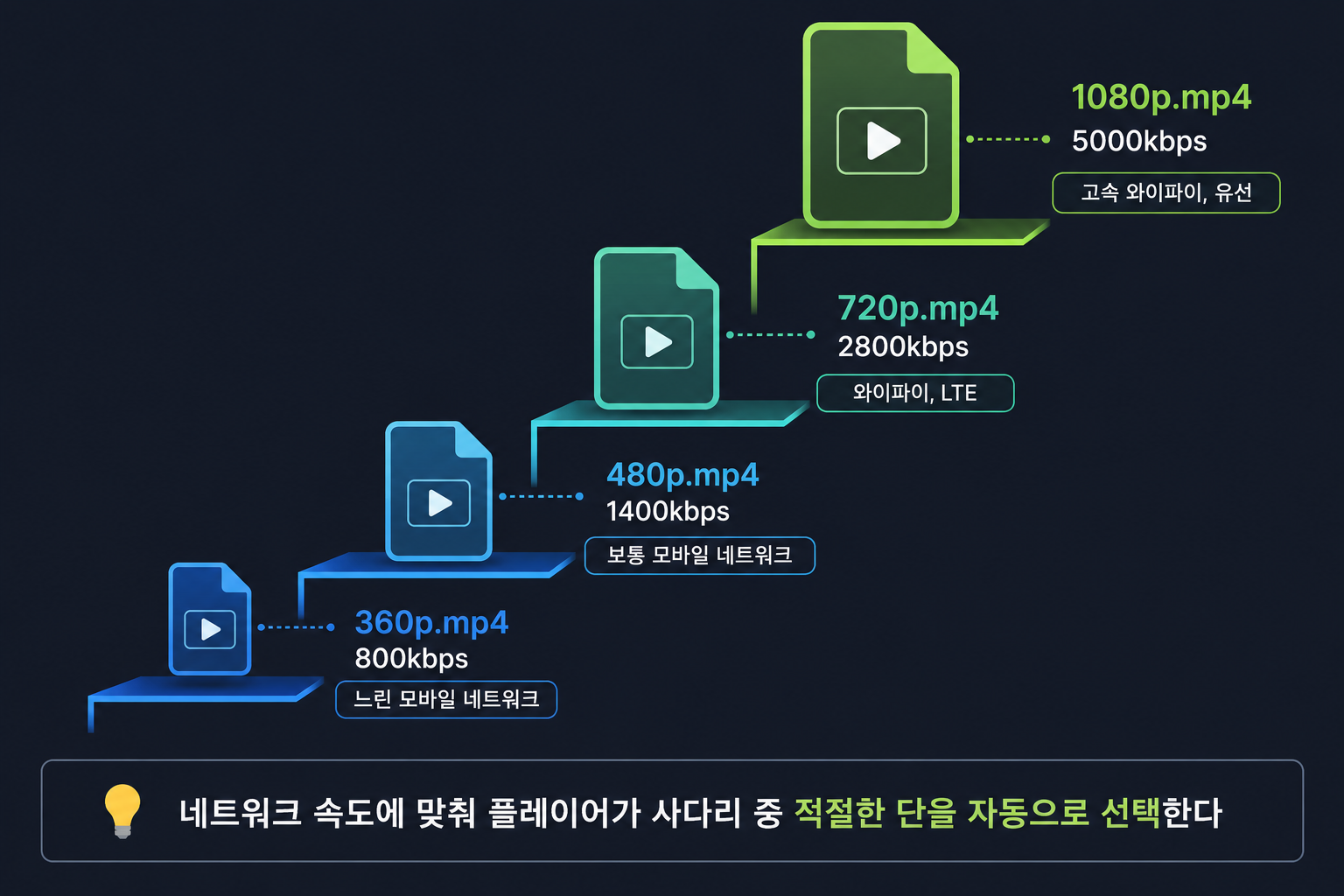
일반적인 ABR 래더
1
2
3
4
5
해상도 비트레이트 용도
360p 800kbps 느린 모바일 네트워크
480p 1400kbps 보통 모바일 네트워크
720p 2800kbps 와이파이, LTE
1080p 5000kbps 고속 와이파이, 유선
콘텐츠 특성에 따라 비트레이트를 조정해야 한다. 애니메이션처럼 단순한 영상은 더 낮은 비트레이트로도 충분하다. Netflix가 콘텐츠마다 다른 ABR 래더를 설계하는 per-title encoding이 바로 이 원리다.
실전 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#!/bin/bash
INPUT="original.mp4"
declare -A LADDER=(
["360p"]="640x360:800k"
["480p"]="854x480:1400k"
["720p"]="1280x720:2800k"
["1080p"]="1920x1080:5000k"
)
for res in "${!LADDER[@]}"; do
IFS=':' read -r size bitrate <<< "${LADDER[$res]}"
ffmpeg -i "$INPUT" \
-c:v h264_nvenc -preset p5 -b:v "$bitrate" \
-vf "scale=$size" \
-c:a aac -b:a 128k \
"output_${res}.mp4"
done
-vf "scale=$size"는 원본 해상도를 목표 해상도로 리사이징하는 필터다. 원본보다 큰 해상도로 업스케일하지 않도록 주의해야 한다. 4K 원본이 아닌데 억지로 4K 화질 단계를 만들면 화질 개선 없이 용량만 커진다.
실무에서는 이런 설정을 코드에 하드코딩하지 않고 업로드 시 원본 해상도·비트레이트를 분석해서, 불필요한 화질(원본이 480p인데 1080p 래더를 만드는 것)을 자동으로 걸러내는 방식을 쓴다고 한다.
HLS/DASH 세그먼트 패키징 — 작은 조각으로 잘라서 배포
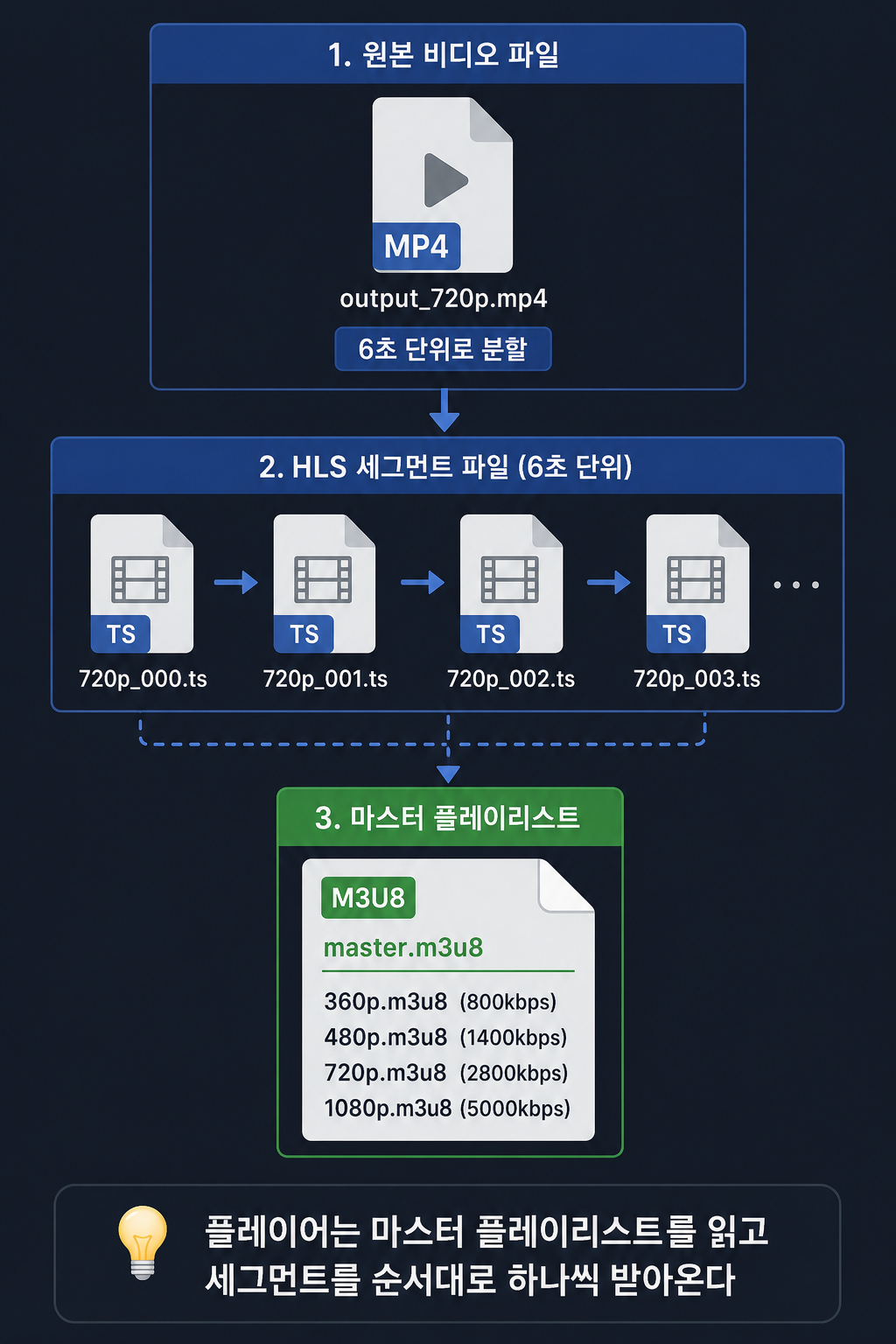
왜 세그먼트로 자르나
화질별 파일까지 만들었으면, 이제 이걸 작은 조각으로 잘라야 한다. 영화 한 편을 통째로 다운로드하게 하면 처음 재생까지 오래 기다려야 한다. 대신 6초짜리 조각들로 잘게 잘라두면, 플레이어는 첫 조각만 받아서 바로 재생을 시작하고 나머지는 재생하면서 순서대로 받아온다.
HLS 세그먼트 + 마스터 플레이리스트
1
2
3
4
5
6
7
8
9
# 화질별 개별 HLS 스트림 생성
for res in 360p 480p 720p 1080p; do
ffmpeg -i "output_${res}.mp4" \
-c copy \ # 이미 인코딩된 파일이므로 재인코딩 없이 복사만
-hls_time 6 \ # 세그먼트 하나당 6초
-hls_playlist_type vod \ # VOD용 플레이리스트
-hls_segment_filename "${res}_%03d.ts" \
"${res}.m3u8"
done
1
2
3
4
5
6
7
8
9
10
# 마스터 플레이리스트 (master.m3u8) — 화질 목록을 담은 최상위 파일
#EXTM3U
#EXT-X-STREAM-INF:BANDWIDTH=800000,RESOLUTION=640x360
360p.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=1400000,RESOLUTION=854x480
480p.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=2800000,RESOLUTION=1280x720
720p.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=5000000,RESOLUTION=1920x1080
1080p.m3u8
-c copy가 핵심이다. 앞 단계에서 이미 화질별로 인코딩을 마쳤기 때문에, 세그먼트로 자르는 이 단계에서는 재인코딩 없이 컨테이너만 다시 포장한다. 재인코딩을 또 하면 시간 낭비고, 화질 손실(트랜스코딩을 여러 번 거치면 화질이 누적으로 나빠지는 현상)도 생긴다.
플레이어는 master.m3u8을 먼저 읽어서 어떤 화질들이 있는지 파악하고, 네트워크 속도를 측정해가며 적절한 {res}.m3u8을 선택해서 재생한다.
DASH도 개념은 같다
DASH는 매니페스트 형식(mpd, XML 기반)만 다를 뿐 개념은 동일하다.
1
2
3
4
5
6
7
8
ffmpeg -i original.mp4 \
-map 0:v -map 0:v -map 0:v -map 0:v -map 0:a \
-c:v h264_nvenc -c:a aac \
-b:v:0 800k -s:v:0 640x360 \
-b:v:1 1400k -s:v:1 854x480 \
-b:v:2 2800k -s:v:2 1280x720 \
-b:v:3 5000k -s:v:3 1920x1080 \
-f dash output.mpd
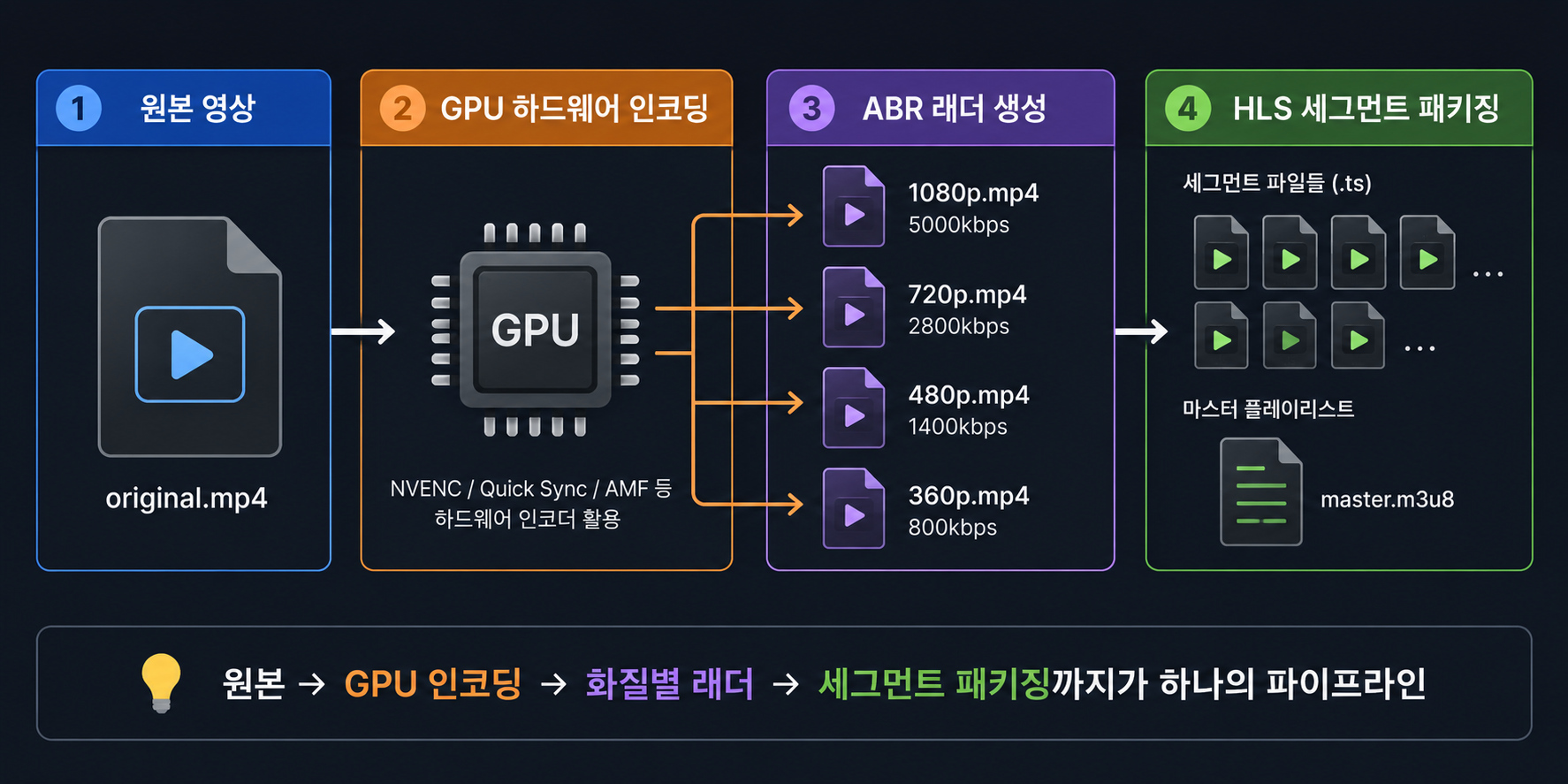
전체 파이프라인 합치기
지금까지 배운 걸 다 합치면 하나의 트랜스코딩 파이프라인이 된다. 원본이 들어오면 GPU로 빠르게 여러 화질을 만들고(하드웨어 인코딩 + ABR 래더), 그걸 작은 조각들로 잘라서 플레이어가 읽을 수 있는 목록과 함께 저장한다(HLS 패키징).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#!/bin/bash
# 실전 트랜스코딩 파이프라인: 원본 → ABR 래더 → HLS 패키징
set -e
INPUT="$1"
OUTPUT_DIR="./hls_output"
mkdir -p "$OUTPUT_DIR"
declare -A LADDER=(
["360p"]="640x360:800k"
["480p"]="854x480:1400k"
["720p"]="1280x720:2800k"
["1080p"]="1920x1080:5000k"
)
# 1단계: 화질별 인코딩 (하드웨어 가속)
for res in "${!LADDER[@]}"; do
IFS=':' read -r size bitrate <<< "${LADDER[$res]}"
echo "인코딩 중: ${res} (${size}, ${bitrate})"
ffmpeg -y -hwaccel cuda -i "$INPUT" \
-c:v h264_nvenc -preset p5 -b:v "$bitrate" \
-vf "scale=$size" \
-c:a aac -b:a 128k \
"${OUTPUT_DIR}/${res}.mp4"
done
# 2단계: HLS 세그먼트 생성
for res in "${!LADDER[@]}"; do
ffmpeg -y -i "${OUTPUT_DIR}/${res}.mp4" \
-c copy -hls_time 6 -hls_playlist_type vod \
-hls_segment_filename "${OUTPUT_DIR}/${res}_%03d.ts" \
"${OUTPUT_DIR}/${res}.m3u8"
done
# 3단계: 마스터 플레이리스트 생성
{
echo "#EXTM3U"
echo "#EXT-X-STREAM-INF:BANDWIDTH=800000,RESOLUTION=640x360"
echo "360p.m3u8"
echo "#EXT-X-STREAM-INF:BANDWIDTH=1400000,RESOLUTION=854x480"
echo "480p.m3u8"
echo "#EXT-X-STREAM-INF:BANDWIDTH=2800000,RESOLUTION=1280x720"
echo "720p.m3u8"
echo "#EXT-X-STREAM-INF:BANDWIDTH=5000000,RESOLUTION=1920x1080"
echo "1080p.m3u8"
} > "${OUTPUT_DIR}/master.m3u8"
echo "완료: ${OUTPUT_DIR}/master.m3u8"
set -e는 스크립트 중간 어느 명령이든 실패하면 즉시 종료하게 한다. 트랜스코딩 파이프라인은 한 화질에서 실패했는데 다음 단계로 넘어가면 깨진 결과물을 그대로 배포할 위험이 있어서, 실패 시 즉시 중단하고 알림을 보내는 방식이 안전하다. -hwaccel cuda는 디코딩(원본을 읽어들이는 과정)도 GPU를 쓰도록 지정한다. 인코딩만 GPU를 쓰고 디코딩은 CPU로 하면 그 구간에서 병목이 생길 수 있다.
실무에서는 이렇게 쓴다
YouTube는 업로드 시 원본 화질까지 포함해 최대 10개 이상의 화질을 자동 생성한다. 자체 개발한 인코딩 칩까지 투입해서 대규모 트랜스코딩 비용을 최적화한다.
Netflix는 per-title encoding으로 콘텐츠마다 ABR 래더의 비트레이트를 다르게 설정한다. 애니메이션은 사다리 단수를 줄이고, 액션 영화는 고비트레이트 구간을 촘촘히 나눈다. 그리고 VMAF 93~95점을 “충분히 좋은 화질”의 기준선으로 삼는다.
Twitch는 라이브 방송이라 인코딩 지연이 곧 방송 지연으로 이어지기 때문에 NVENC/QSV 하드웨어 인코딩이 사실상 필수다. -tune zerolatency, B-Frame 비활성화와 함께 적용한다.
실무 운영 팁으로는 트랜스코딩 서버를 CPU(품질 우선, VOD)와 GPU(속도 우선, 라이브·대량 처리)로 분리 운영하는 경우가 많다고 한다.
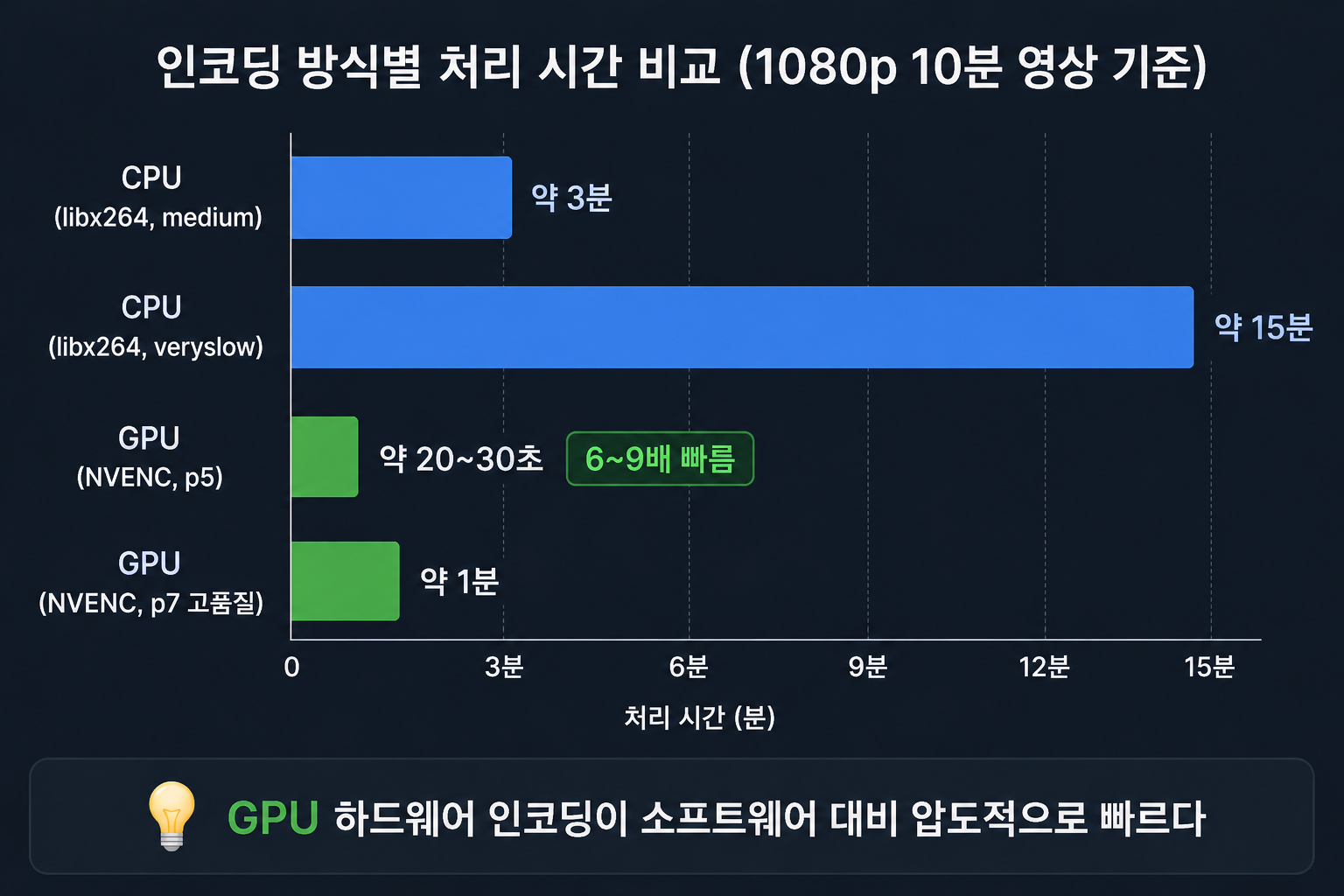
수치로 확인하기
인코딩 방식별 처리 속도 (1080p 10분 영상 기준, 체감치)
| 인코딩 방식 | 처리 시간 | 비고 |
|---|---|---|
| CPU (libx264, medium) | 약 3분 | 압축 효율 최고 |
| CPU (libx264, veryslow) | 약 15분 | 파일 크기 최소화 |
| GPU (NVENC, p5) | 약 20~30초 | 6~9배 빠름 |
| GPU (NVENC, p7 고품질) | 약 1분 | 속도·품질 균형 |
ABR 전환 품질 기준
| 지표 | 정상 | 문제 |
|---|---|---|
| 화질 전환 빈도 | 재생 중 1~2회 이하 | 자주 오르내림 (네트워크 불안정 또는 래더 설계 문제) |
| 초기 버퍼링 시간 | 2초 이내 | 5초 이상이면 첫 세그먼트가 너무 크거나 CDN 응답 느림 |
| 세그먼트 길이 | 6초 (HLS 표준) | 2초 미만이면 오버헤드 증가, 10초 이상이면 화질 전환 지연 |
화질 지표 기준선
| 지표 | 매우 좋음 | 적당함 | 문제 있음 |
|---|---|---|---|
| PSNR | 40dB 이상 | 30~40dB | 30dB 미만 |
| SSIM | 0.98 이상 | 0.90~0.98 | 0.90 미만 |
| VMAF | 93 이상 | 80~93 | 80 미만 |
배포 전에는 이 체크리스트를 확인한다.
1
2
3
4
1. VMAF로 각 화질별 압축 결과가 기준(93점 등)을 만족하는지 확인
2. master.m3u8이 모든 화질을 올바른 순서로 나열하는지 확인
3. 세그먼트 파일이 실제로 생성됐는지, 개수가 예상과 맞는지 확인
4. 여러 네트워크 환경에서 실제 재생 테스트 — 화질 전환이 매끄러운지 확인
VMAF 평균 점수만 보지 말고 프레임별 최저 점수(min)도 같이 확인하는 게 좋다고 배웠다. 평균은 93점이어도 특정 프레임(빠른 장면 전환 등)에서 70점대로 떨어지는 구간이 있으면, 그 부분만 사람이 체감할 때 뚝뚝 끊기는 느낌을 받을 수 있기 때문이다.
코덱 시리즈를 마무리하며
압축의 기본 원리(공간적·시간적 중복 제거)부터 시작해서 H.264, H.265, AV1 같은 비디오 코덱, Opus·AAC 오디오 코덱, 그리고 이번에 화질 측정과 실전 트랜스코딩까지 왔다.
처음 이 시리즈를 시작할 때는 “왜 1080p가 4Mbps면 충분한가요?”라는 질문에 답을 못 했었는데, 이제는 CRF, VMAF, ABR 래더까지 연결해서 그 숫자들이 어디서 나온 건지 설명할 수 있게 됐다. 감으로 판단하던 걸 숫자로 검증하는 법을 배운 게 이번 시리즈에서 가장 크게 남는 부분이다.
다음은 실제로 트랜스코딩 서버를 하나 직접 구성해보면서, 여기서 배운 걸 프로젝트에 적용해볼 생각이다.