671 GB짜리 영상이 4 GB가 되는 이유 — 코덱 기초부터 H.264까지
HLS, DASH, WebRTC를 공부하면서 계속 넘어갔던 질문이 하나 있었다.
“프로토콜이 영상을 쪼개서 전송한다는 건 알겠는데, 그 안에 담긴 데이터는 어떻게 이렇게 작아지는 거지?”
DASH 포스트를 쓸 때 ABR(적응형 비트레이트)을 설명하면서 4Mbps, 8Mbps 같은 숫자를 아무렇지 않게 썼는데, 막상 “왜 1080p가 4Mbps면 충분한가요?”라는 질문에 제대로 답을 못 했다. 그때 코덱을 제대로 한 번 파야겠다고 생각했다.
아무것도 안 하면 얼마나 클까
시작은 숫자부터다.
1080p 30fps 영상을 아무 압축 없이 저장하면 얼마나 클까. 직접 계산해봤다.
픽셀 하나는 R(빨강), G(초록), B(파랑) 세 값이다. 각각 0~255를 표현하는 8비트 = 1바이트. 픽셀 하나당 3바이트다.
1
2
3
4
5
6
7
8
1920(가로) × 1080(세로) = 2,073,600 픽셀
2,073,600 × 3바이트 = 6,220,800바이트 ≈ 6 MB (프레임 1장)
30fps → 1초에 30장
6 MB × 30 = 180 MB/초
1시간 = 3600초
180 MB × 3600 = 648,000 MB ≈ 648 GB
648 GB. 집에 있는 SSD 전체 용량이 1TB면 그 절반 이상이 영상 하나에 들어간다.
이걸 인터넷으로 스트리밍하려면 초당 약 1.5 Gbps가 필요하다. 대한민국 가정용 인터넷이 기가급이어도 이건 불가능한 수치다. 그리고 그 영상을 저장할 서버 비용은 생각하기도 싫다.
H.264로 압축하면 같은 영상이 1~4 GB 수준이 된다. 약 1/150에서 1/670으로 줄어든다. 이게 어떻게 가능한지가 오늘 주제다.

압축의 두 가지 축
코덱이 데이터를 줄이는 방법은 크게 두 가지다. 하나는 같은 프레임 안에서 반복되는 정보를 제거하는 것이고, 다른 하나는 연속된 프레임 사이에서 반복되는 정보를 제거하는 거다.
각각 공간적 중복 제거와 시간적 중복 제거라고 부른다.
이 두 가지만 이해하면 H.264 내부 구조의 80%는 설명이 된다.
공간적 중복 제거 — 한 프레임 안의 반복을 없앤다
맑은 날 하늘 사진이 있으면 위 절반이 전부 비슷한 파란색이다. 이걸 픽셀 단위로 저장하면 “파랑, 파랑, 파랑…” 100만 번 반복하는 셈이다. 명백한 낭비다.
공간적 중복 제거는 이 반복을 없애는 과정이다. 코덱이 이걸 처리하는 순서는 세 단계다.
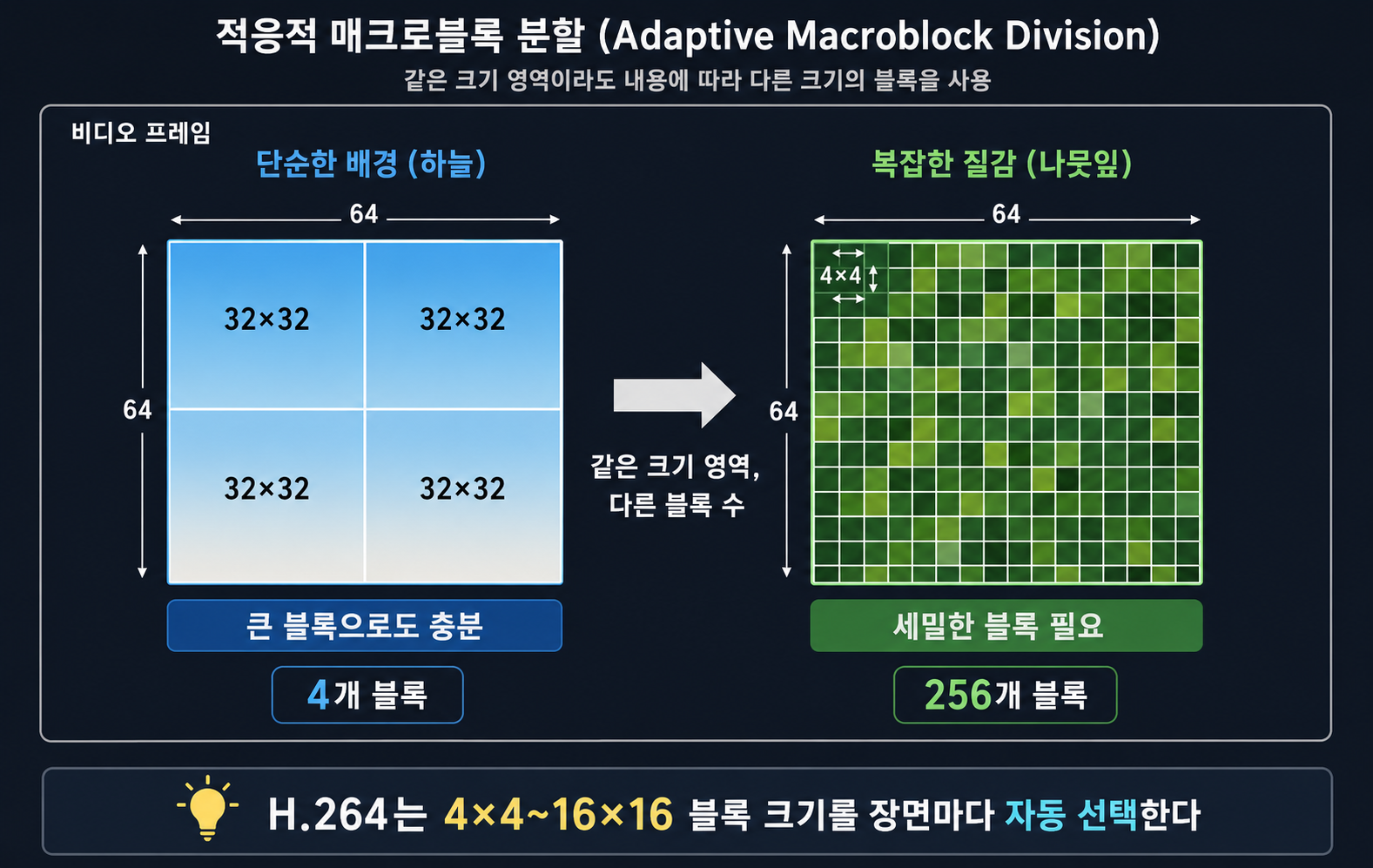
매크로블록으로 쪼갠다
먼저 프레임 전체를 처리하는 게 아니라 작은 블록으로 나눈다.
기본 단위는 매크로블록(Macroblock)이라고 부르는 16×16 픽셀 블록이다. 1080p 프레임이면 가로 120개, 세로 68개 = 총 8,160개 블록으로 나뉜다. 각 블록을 독립적으로 처리한다.
왜 블록 단위로 나누냐면, 화면의 단순한 부분과 복잡한 부분을 다르게 처리하기 위해서다.
H.264는 블록 크기를 상황에 따라 바꿀 수 있다. 파란 하늘처럼 색이 균일한 단순한 영역은 16×16 블록 하나로 충분하다. 나뭇잎이나 글씨처럼 경계선이 많고 복잡한 영역은 8×8, 심지어 4×4까지 잘게 쪼갠다. 작을수록 더 정밀하게 표현할 수 있다.
인코더는 가능한 모든 블록 크기 조합을 계산해서 오차가 가장 작고 데이터가 가장 적은 조합을 선택한다. preset이 느릴수록 이 탐색을 더 철저히 해서 파일이 더 작아지는 거다.
인트라 예측 — 주변 블록을 보고 예측한다
블록을 나눴으면 각 블록의 내용을 예측한다.
아직 처리하지 않은 블록은 이미 처리된 왼쪽 블록과 위쪽 블록에 둘러싸여 있다. 주변 블록의 색상을 보면 이 블록이 어떤 색일지 어느 정도 예측할 수 있다.
예측 방향은 9가지다. 위에서 아래로, 왼쪽에서 오른쪽으로, 대각선 방향 여러 가지. 인코더는 9가지 방향을 모두 시도해서 실제값과 예측값의 차이(오차)가 가장 작은 방향을 선택한다.
파란 하늘 영역이라면 왼쪽 블록도 파랗고 위쪽 블록도 파랗다. 예측: 파란색. 실제: 파란색. 오차: 거의 0. 저장할 데이터: 거의 없다.
코덱이 저장하는 건 블록 전체 픽셀값이 아니라 “예측 방향 번호 + 예측과 실제의 차이”다. 예측이 잘 맞을수록 차이가 작아지고 파일이 줄어든다.
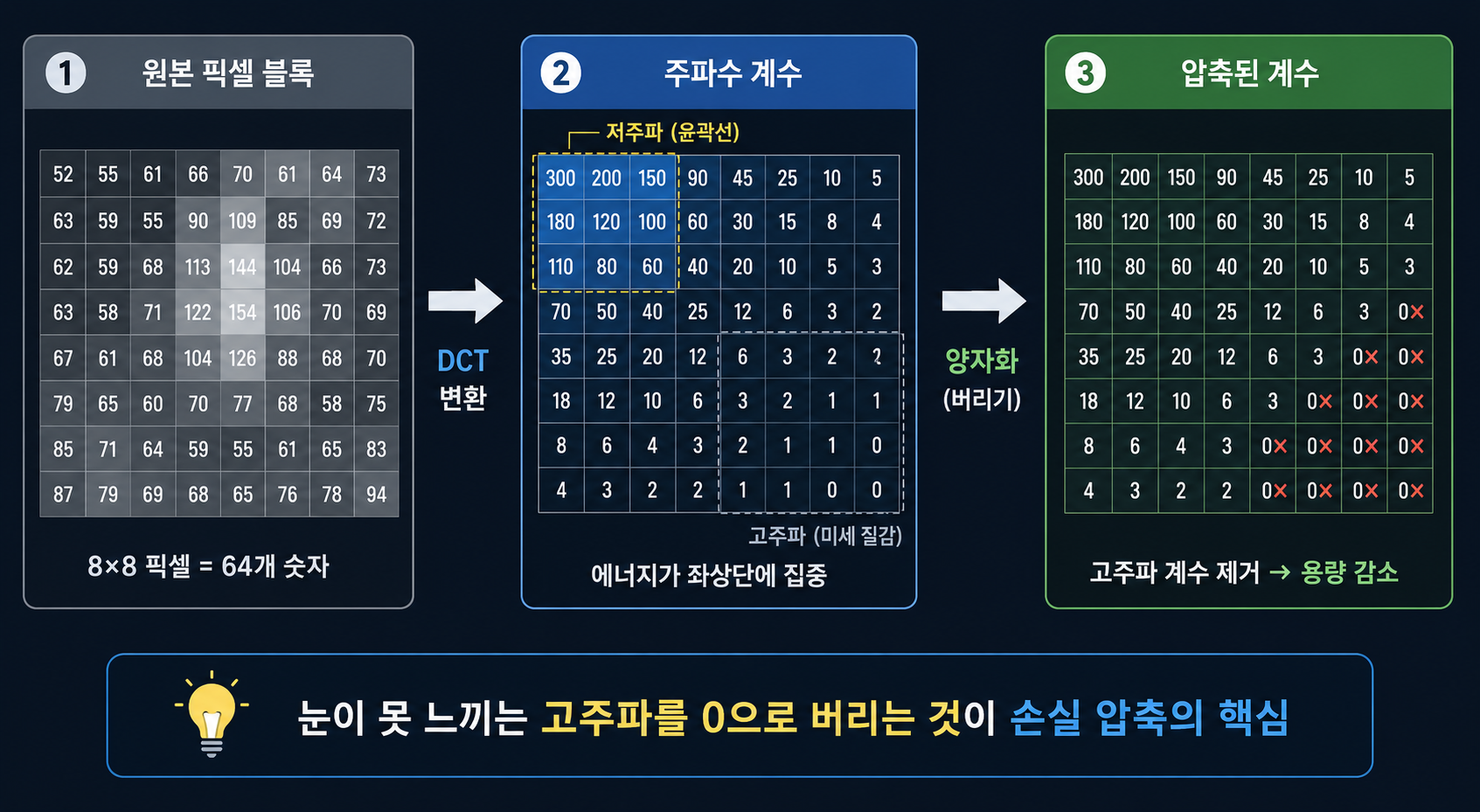
DCT + 양자화 — 눈이 못 보는 걸 버린다
예측 오차가 나왔으면 DCT(이산 코사인 변환)를 적용한다.
DCT는 픽셀값들의 패턴을 주파수 성분으로 분해하는 수학 변환이다. 음악을 저음과 고음으로 분리하듯이, 픽셀 패턴을 “저주파(전체적인 밝기·색조)”와 “고주파(미세한 경계선 디테일)”로 나눈다.
변환 결과를 보면 왼쪽 위에 저주파 성분이 모이고 오른쪽 아래로 갈수록 고주파 성분이 된다. 그리고 오른쪽 아래 영역은 대부분 0에 가까운 값이다.
1
2
3
4
5
6
7
8
9
DCT 결과 예시 (8×8 계수):
[ 72, -3, 1, 0, 0, 0, 0, 0 ]
[ -8, 2, 0, 0, 0, 0, 0, 0 ]
[ 2, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0 ]
저주파 성분(왼쪽 위)은 전체적인 색조와 밝기라서 보존해야 한다. 고주파 성분(오른쪽 아래)은 미세한 경계선 디테일인데, 인간의 눈이 이 수준의 디테일엔 둔감하다. 그래서 버린다.
버리는 과정이 양자화다. DCT 계수를 일정 숫자로 나눠서 소수점을 버린다. 고주파 영역일수록 큰 수로 나눠서 더 많이 버린다.
1
2
3
4
5
6
양자화 후:
[ 36, -1, 0, 0, 0, 0, 0, 0 ]
[ -2, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 0, 0 ]
...
(대부분 0)
0이 압도적으로 많아진다. 0은 저장 안 해도 되니까 파일이 줄어든다.
이 과정에서 정보가 실제로 손실된다. 고주파를 버리면 원본으로 완벽하게 복원이 안 된다. 그런데 눈이 그 차이를 못 느낀다. 인간 시각의 약점을 이용한 설계다.
얼마나 강하게 양자화할지를 결정하는 게 CRF 값이다. 이건 뒤에서 다시 설명한다.
시간적 중복 제거 — 연속 프레임 사이의 반복을 없앤다
공간적 중복 제거만으로는 부족하다. 영상의 진짜 강력한 압축은 시간적 중복에서 나온다.
뉴스 앵커가 말하는 30초짜리 영상을 생각해보자. 30초 동안 배경 스튜디오는 전혀 바뀌지 않는다. 앵커 얼굴 대부분도 그대로다. 입과 눈만 조금씩 움직인다.
이 30초를 900장 프레임 모두 공간적 중복 제거만 해서 저장하면 여전히 많은 데이터가 필요하다. 하지만 900장 대부분이 이전 프레임과 거의 똑같다면, 차이만 기록하면 어떨까.
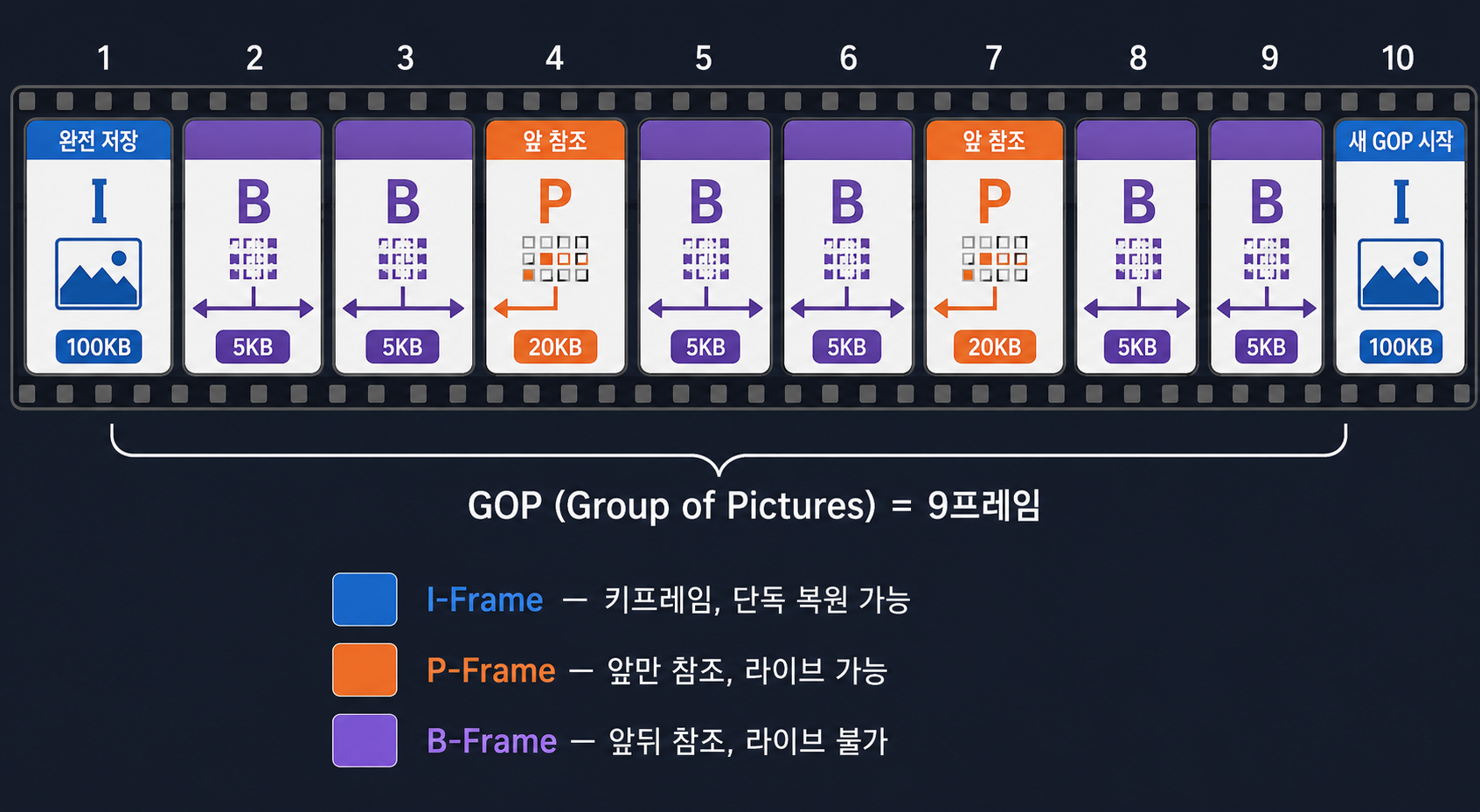
이게 I·P·B 프레임의 원리다.
I-Frame — 기준이 되는 완전한 프레임
I-Frame(Intra-coded Frame)은 다른 프레임의 도움 없이 혼자서 화면을 완성할 수 있는 프레임이다. JPEG 사진 한 장과 비슷하다고 보면 된다.
파일 크기가 가장 크다. 공간적 중복 제거(인트라 예측 + DCT + 양자화)만 적용한 결과를 통째로 저장해야 하기 때문이다.
I-Frame은 두 가지 중요한 역할을 한다.
첫째는 기준점이다. P·B-Frame은 이전 프레임을 참조해서 차이만 저장하는데, 그 체인의 시작점이 I-Frame이다. I-Frame이 없으면 뒤에 오는 P·B-Frame들이 기준을 잃어서 화면이 깨진다.
둘째는 탐색 기준점이다. 유튜브에서 영상 중간을 클릭하면 바로 그 지점부터 재생된다. 코덱은 클릭한 지점 근처의 I-Frame으로 점프하고 거기서부터 디코딩을 시작한다. I-Frame 없이는 임의 탐색이 불가능하다.
P-Frame — 앞 프레임과의 차이만
P-Frame(Predictive-coded Frame)은 이전 I 또는 P 프레임을 참조해서 달라진 부분만 저장한다.
핵심 개념이 모션 벡터다. 이전 프레임에서 현재 블록과 가장 비슷한 위치를 찾아서, 그 위치의 좌표 차이를 기록한다.
1
2
3
4
5
6
7
이전 프레임 공 위치: (100, 200)
현재 프레임 공 위치: (120, 195)
저장: 모션 벡터 (+20, -5)
"오른쪽 20픽셀, 위로 5픽셀 이동했다"
블록 전체 픽셀값 대신 벡터 두 숫자만 저장
물론 블록이 단순히 이동만 하는 게 아니라 조명이 바뀌거나 물체가 변형되기도 한다. 그 차이(예측 오차)도 같이 저장한다. 오차가 작을수록 저장할 데이터가 적다.
P-Frame의 크기는 보통 I-Frame의 30~50% 수준이다.
B-Frame — 앞뒤 프레임을 모두 참조
B-Frame(Bi-directionally predicted Frame)은 이전 프레임과 다음 프레임을 모두 참조한다.
공이 왼쪽에서 오른쪽으로 날아가는 장면을 생각해보자.
- 50번 프레임: 공이 왼쪽에 있다
- 51번 프레임 (B-Frame): 공이 중간쯤에 있다
- 52번 프레임: 공이 오른쪽에 있다
51번을 저장할 때, P-Frame처럼 50번만 참조하면 오차가 크다. 하지만 50번과 52번을 동시에 참조하면 “50번에선 왼쪽, 52번에선 오른쪽이니까 51번은 중간”이라고 훨씬 정확하게 예측할 수 있다. 오차가 줄고, 파일이 줄어든다. 크기가 I-Frame의 10~20% 수준까지 내려간다.
단, 51번을 처리하려면 52번이 먼저 있어야 한다. 미래 프레임이 필요하다. 그래서 라이브 스트리밍에서는 B-Frame을 쓸 수 없다. 지금 방송 중인 프레임 다음에 올 프레임은 아직 촬영도 안 됐기 때문이다.
1
2
3
4
5
6
# 라이브 스트리밍에서 B-Frame 비활성화
ffmpeg -i input -c:v libx264 -tune zerolatency ...
# -tune zerolatency가 B-Frame을 자동으로 0으로 설정한다
# 또는 명시적으로
ffmpeg -i input -c:v libx264 -bf 0 ...
GOP — 프레임의 묶음 단위
GOP(Group of Pictures)는 I-Frame 하나부터 다음 I-Frame 직전까지의 프레임 묶음이다.
1
2
I──P──B──B──P──B──B──P──B──B──I──P──B──B──...
│◄──────── GOP 크기 = 10 ─────────►│
GOP 크기는 트레이드오프다.
GOP를 크게 잡으면(I-Frame 드물게) P·B-Frame 비중이 늘어나서 파일이 작아진다. 대신 영상 중간을 탐색할 때 가장 가까운 I-Frame까지 거리가 멀어서 점프가 느려진다.
GOP를 작게 잡으면(I-Frame 자주) 탐색이 빠르고 네트워크 오류 시 빠르게 복구된다. 대신 I-Frame이 자주 나오니까 파일이 커진다.
YouTube가 업로드 권장사항으로 “키프레임 간격 2초”를 명시하는 이유가 여기 있다. 30fps면 GOP = 60이다. 탐색 경험과 파일 크기의 균형을 잡은 값이다.
1
2
3
# GOP 크기 설정
ffmpeg -i input.mov -c:v libx264 -g 60 output.mp4
# 30fps 기준으로 2초마다 I-Frame
실제로 패킷 손실 상황에서 이 차이가 드러난다. 라이브 스트리밍 중 네트워크가 순간적으로 끊기면 화면이 깨지는데, 다음 I-Frame이 도착할 때까지 복구되지 않는다. GOP가 크면 클수록 깨진 채로 있는 시간이 길어진다.
코덱 vs 컨테이너 — 자주 혼동하는 개념
코덱 공부하면서 처음에 제일 많이 헷갈렸던 게 이거다.
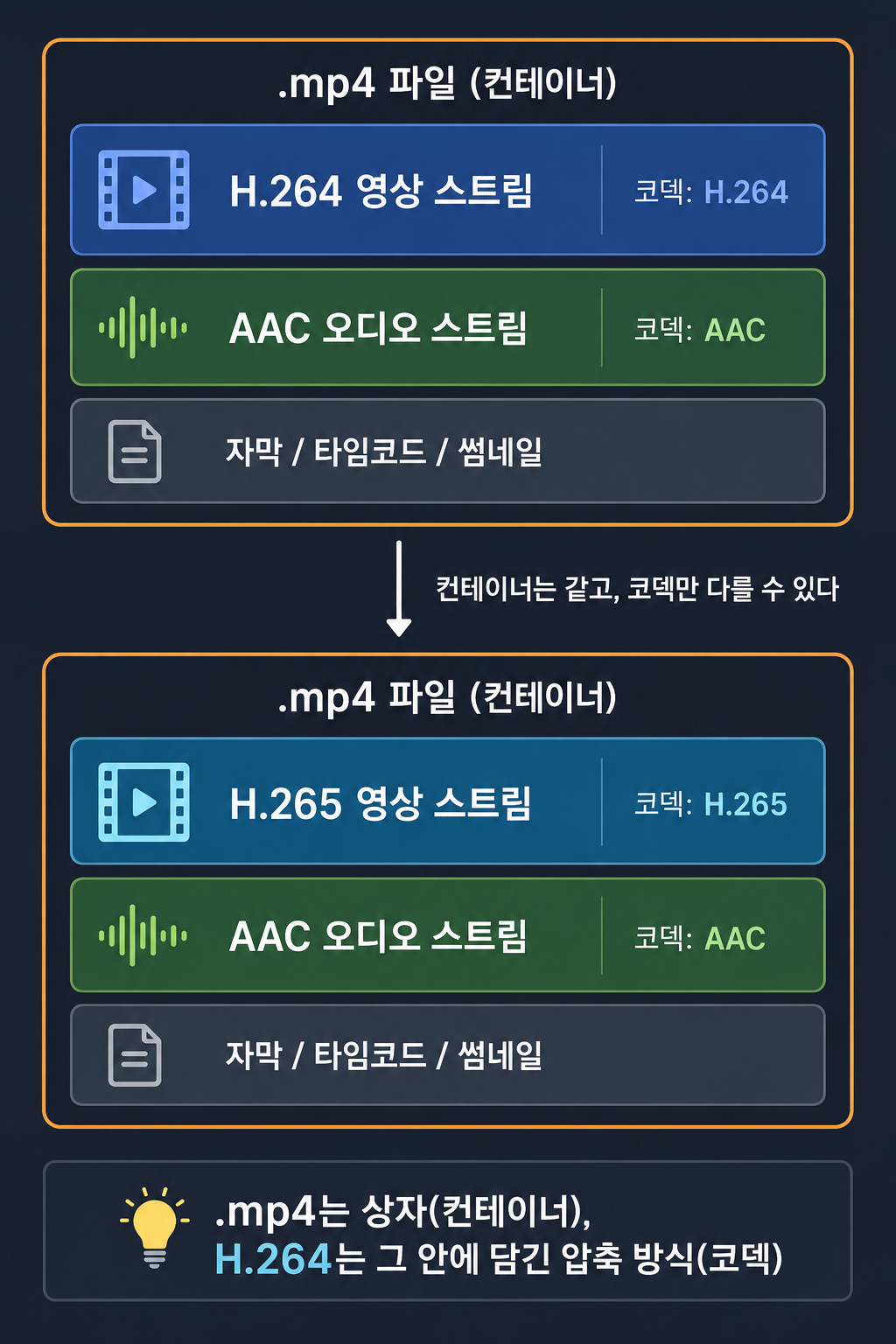
.mp4 = H.264라고 무의식적으로 생각하고 있었다. 틀렸다.
.mp4는 컨테이너다. 영상 스트림, 오디오 스트림, 자막, 메타데이터를 하나의 파일로 묶는 포장지다. H.264는 그 안에 들어가는 압축 방식(코덱)이다. 둘은 완전히 다른 개념이다.
1
2
3
4
5
video.mp4 (컨테이너)
├── 비디오 스트림 → codec: H.264 (혹은 H.265, AV1 등)
├── 오디오 스트림 → codec: AAC (혹은 MP3, Opus 등)
├── 자막 트랙
└── 메타데이터 (제목, 해상도, 길이...)
같은 .mp4 안에 H.265나 AV1이 들어갈 수도 있다. .webm은 컨테이너고 VP9이나 AV1을 담는다. .mkv는 거의 모든 코덱을 담을 수 있다.
컨테이너별 주로 쓰이는 조합은 이렇다.
| 컨테이너 | 주 비디오 코덱 | 주 오디오 코덱 | 용도 |
|---|---|---|---|
.mp4 | H.264, H.265, AV1 | AAC | 범용, 스트리밍 |
.webm | VP9, AV1 | Opus | 웹 브라우저 |
.mkv | 거의 모두 | 거의 모두 | 로컬 저장, 다중 자막 |
.mov | H.264, ProRes | AAC | 애플, 영상 편집 |
코덱이 뭔지 확인하려면 ffprobe를 쓴다.
1
2
3
4
5
6
7
8
ffprobe -v error -select_streams v:0 \
-show_entries stream=codec_name,profile,pix_fmt \
-of default=noprint_wrappers=1 input.mp4
# 출력 예시:
# codec_name=h264
# profile=High
# pix_fmt=yuv420p
YUV — 색을 밝기와 색상으로 분리하는 이유
공간적 중복 제거 전에 색 공간 변환이 먼저 일어난다.
카메라는 RGB로 데이터를 수집한다. 그런데 코덱은 그걸 그대로 쓰지 않고 YUV로 바꾼다.
Y는 밝기(Luma), U·V는 색상(Chroma)이다.
왜 바꾸냐면 인간 눈의 특성 때문이다.
밝기 변화엔 극도로 예민하다. 어두운 방에서 작은 움직임도 금방 알아챈다. 반면 색상 변화엔 상당히 둔감하다. 흑백 사진을 봐도 사물을 다 알아볼 수 있는 게 그 증거다. 붉은 톤이 5% 더 강한지 덜 강한지는 나란히 놓고 보지 않으면 잘 모른다.
RGB는 세 채널을 동등하게 취급한다. 빨간 채널을 줄이면 화면이 이상하게 보인다. G 채널을 줄여도 마찬가지다. 세 채널이 모두 밝기 정보를 담고 있어서 어느 것도 마음대로 줄이기 어렵다.
YUV로 바꾸면 다르다. Y가 밝기 전체를 담당하고, U·V는 순수하게 색상 차이만 담는다. 그러면 눈이 잘 못 느끼는 U·V를 줄여도 화면이 자연스럽게 보인다. Y만 선명하면 사람은 화질이 좋다고 느낀다.
1
2
3
4
RGB → YUV 변환 (근사값):
Y = 0.299R + 0.587G + 0.114B ← 밝기
U = -0.147R - 0.289G + 0.436B ← 색차 (청색 방향)
V = 0.615R - 0.515G - 0.100B ← 색차 (적색 방향)

크로마 서브샘플링 — 색상 정보를 얼마나 버릴지
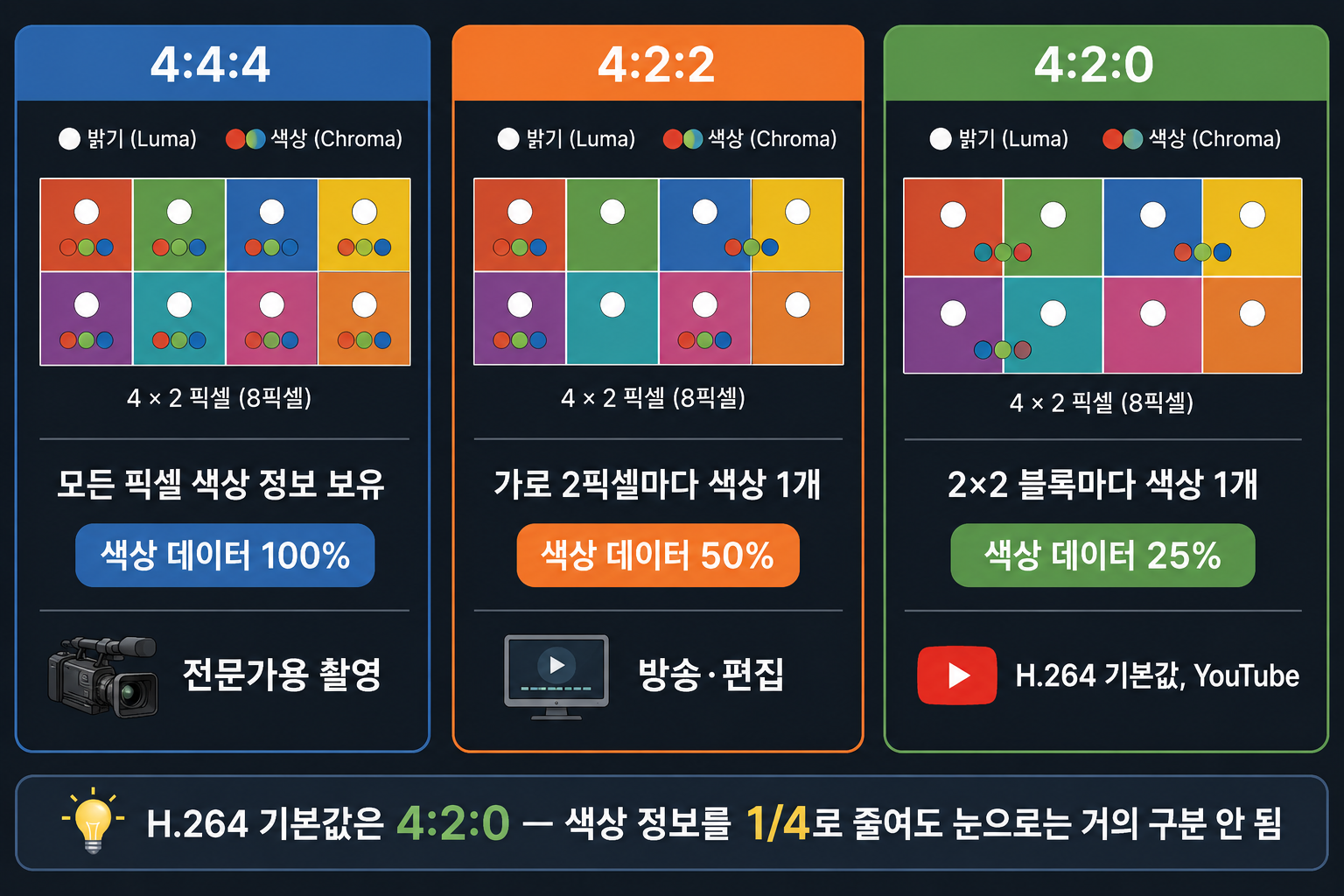
YUV로 바꿨으면, U·V(Chroma) 채널의 해상도를 낮춘다. 이게 크로마 서브샘플링이다.
세 가지 방식이 있다.
4:4:4 — 완전한 색상 보존
모든 픽셀에 Y, U, V 세 채널이 다 있다.
1
2
3
픽셀 배치 (4×2 기준):
Y U Y U Y U Y U
Y U Y U Y U Y U
색상 정보 손실 없음. 편집용 원본 영상, 의료 영상, 영화 마스터링에 쓴다. 파일이 가장 크다.
4:2:2 — 수평으로 색상 절반
수평 방향으로 2픽셀당 색상 하나를 공유한다.
1
2
3
픽셀 배치:
Y U Y Y U Y Y U Y Y U Y
Y U Y Y U Y Y U Y Y U Y
데이터가 4:4:4 대비 약 66% 수준이다. 색보정이 필요한 방송 촬영, 색보정 후 배포 전 중간 단계에서 쓴다.
4:2:0 — H.264 기본값
수평·수직 모두 2픽셀당 색상 하나를 공유한다. 2×2 픽셀 묶음당 색상 정보가 하나다.
1
2
3
픽셀 배치:
Y U Y Y U Y
Y Y Y Y
데이터가 4:4:4 대비 50% 수준이다. 색상 데이터가 1/4로 줄어든다.
눈이 그 차이를 못 느끼기 때문에 스트리밍 배포 표준이 됐다. YouTube, Netflix, Twitch 모두 최종 배포는 4:2:0이다.
1
2
# 4:2:0 명시 (YouTube 권장)
ffmpeg -i input.mov -c:v libx264 -pix_fmt yuv420p output.mp4
4:2:0의 한계 — 색 밴딩
주의할 게 있다. iPhone이나 일반 미러리스로 찍은 영상이 4:2:0인데, 이걸 Premiere에서 색보정하면 하늘 그라데이션이 매끄럽지 않고 계단처럼 끊기는 현상이 생기기도 한다.
색 밴딩(Color Banding)이다. 색상 정보가 이미 많이 줄어든 상태에서 색을 더 강하게 바꾸려 하면 한계가 드러난다.
색보정이 중요한 촬영은 4:2:2 이상을 지원하는 카메라를 써야 한다. 소니 FX시리즈나 블랙매직 같은 시네마 카메라가 4:2:2를 지원하는 이유다.
촬영 → 색보정 → 배포 과정으로 보면 이렇게 된다.
1
2
3
촬영: 4:2:2 (색보정 여유 확보)
색보정: 4:2:2 유지
배포: 4:2:0으로 재인코딩 (파일 크기 최적화)
H.264 — 2003년부터 지금까지 현역인 코덱
H.264는 2003년에 ITU-T와 ISO/MPEG이 공동으로 표준화했다. 공식 명칭은 H.264 또는 MPEG-4 AVC(Advanced Video Coding)다.
등장 전엔 MPEG-2가 DVD와 방송 표준이었는데, H.264는 같은 화질을 약 절반의 용량으로 담았다. 이게 2005년 YouTube 창업과 맞물리면서 인터넷 스트리밍 시대를 열었다.
2024년 기준으로 인터넷 트래픽의 약 80%가 아직 H.264다. 20년이 지났는데도 현역인 이유는 단 하나다. TV, 스마트폰, 브라우저, 게임기까지 거의 모든 기기가 H.264 하드웨어 가속 디코딩을 지원하기 때문이다. 소프트웨어로 디코딩하면 배터리를 많이 쓰는데, 하드웨어 지원이 있으면 훨씬 효율적이다.
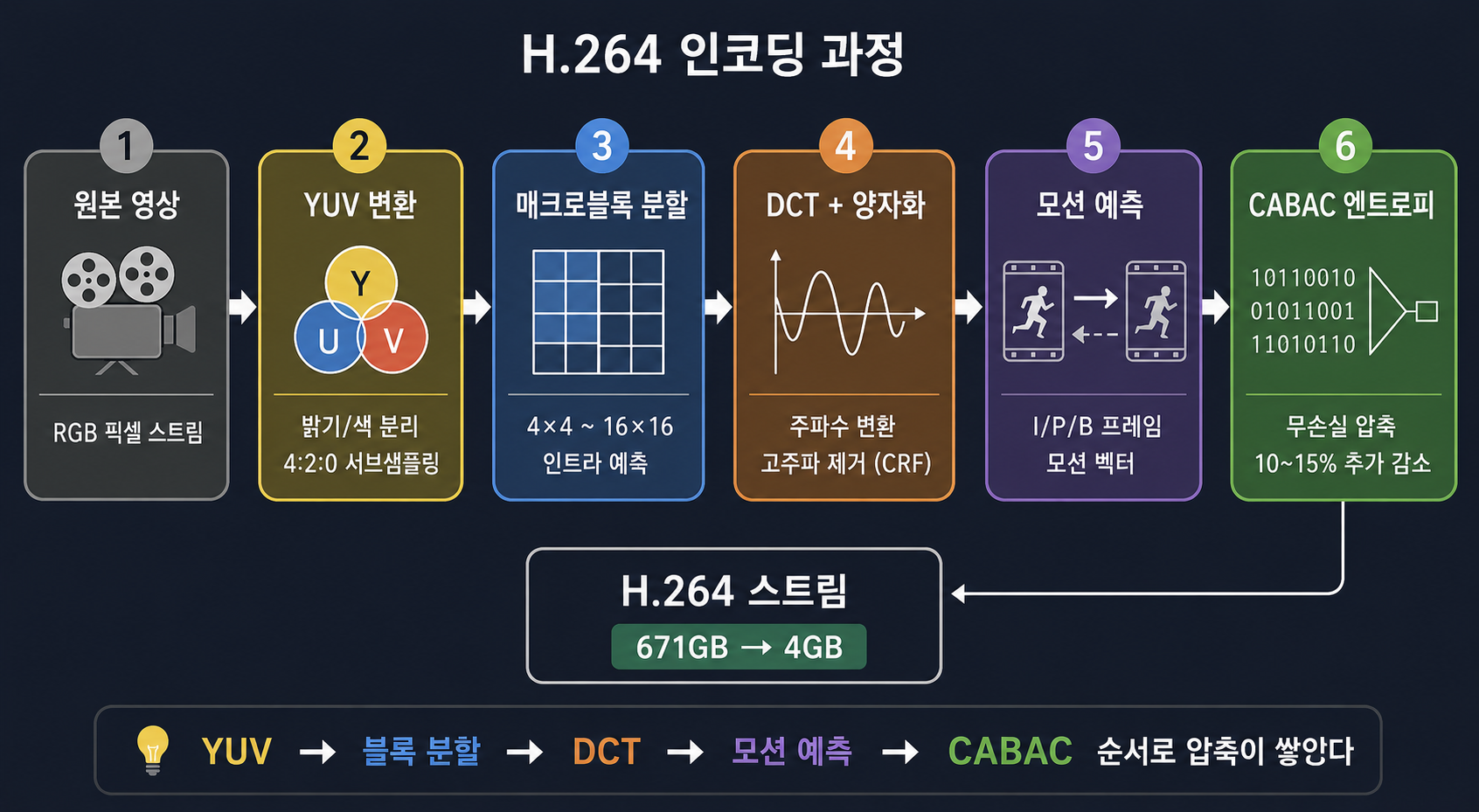
H.264 압축의 세 층
H.264 인코딩 파이프라인을 보면 세 층이 있다.
1
2
3
4
5
6
7
8
9
RAW 프레임 (YUV 변환 완료)
↓
1층: 인트라/인터 예측 → 예측 오차 계산
↓
2층: DCT + 양자화 → 고주파 제거
↓
3층: CABAC → 무손실 최종 압축
↓
H.264 비트스트림
앞에서 공간적·시간적 중복 제거를 설명했는데, 그게 1층에 해당한다. 2층은 이미 DCT에서 다뤘다. 3층만 추가로 설명하면 된다.
CABAC — 마지막으로 한 번 더
DCT와 양자화를 거치고 나면 숫자 배열에 0이 압도적으로 많다. CABAC은 이 패턴을 이용해서 무손실로 10~15% 추가 압축한다.
원리는 모스부호와 같다. 자주 나오는 패턴에 짧은 코드를 배정하고, 드물게 나오는 패턴에 긴 코드를 배정한다. E가 .이고 Z가 --..인 것처럼.
0이 10개 연속으로 나오면 “0 열 개”를 열 번 저장하는 게 아니라 “0이 10개” 라는 특수 코드 하나로 표현한다. 주변 블록의 패턴을 보고 현재 숫자가 0일 확률이 높으면 아주 짧은 코드를 쓴다. 이게 “Context-Adaptive”의 의미다.
정보를 하나도 버리지 않는다. 복원하면 완벽하게 같은 숫자가 나온다. 표현 방식만 더 효율적으로 바꾸는 거다.
CABAC은 Main과 High Profile에서만 쓸 수 있다. Baseline은 더 단순한 CAVLC를 쓰는데 압축률이 10~15% 낮다. Baseline을 쓸 이유가 없다면 High Profile을 쓰는 게 맞다.
CRF — 화질과 파일 크기의 손잡이
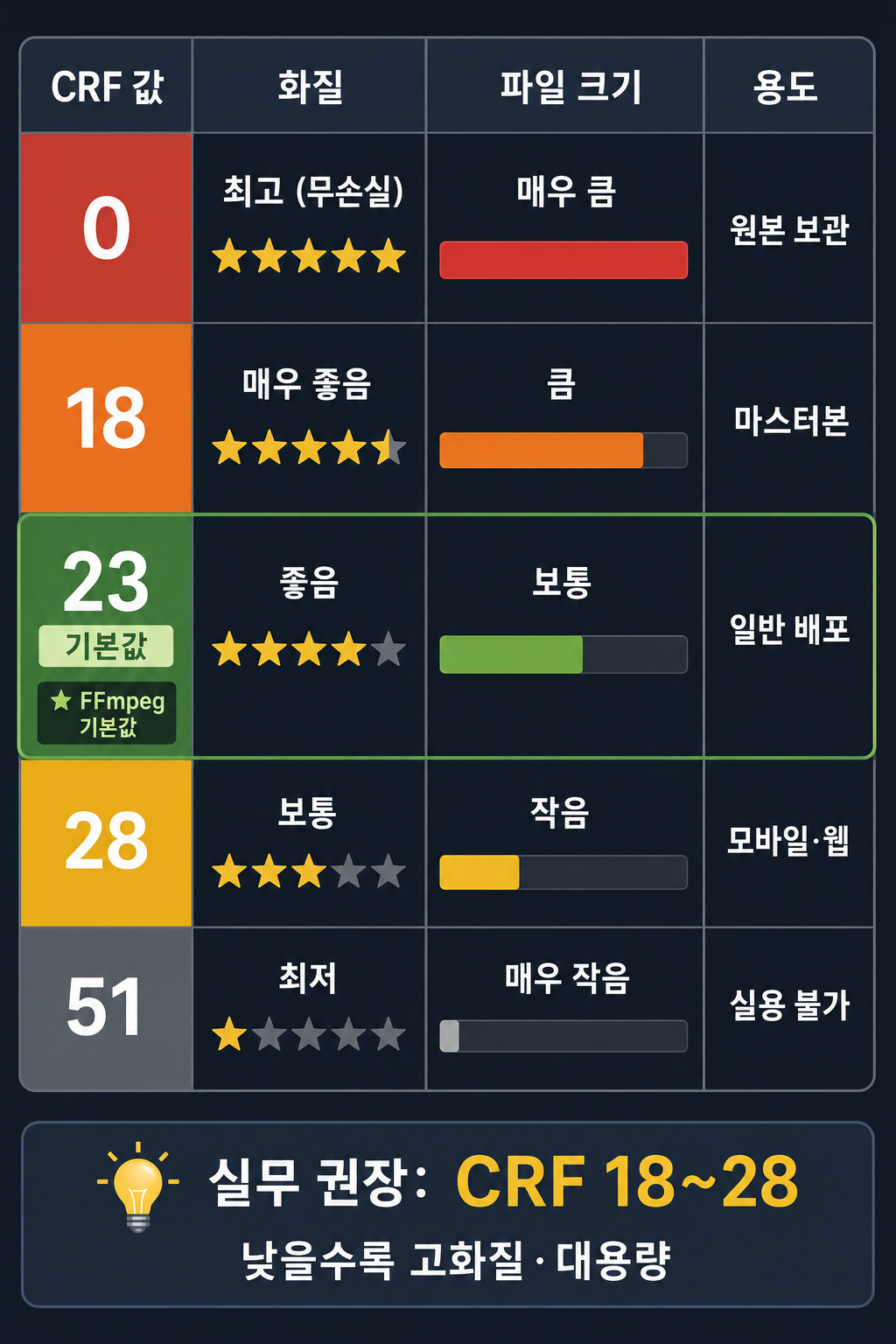
CRF(Constant Rate Factor)는 양자화 강도를 결정한다.
0부터 51까지다. 낮을수록 화질이 좋고 파일이 크다. 높을수록 화질이 나쁘고 파일이 작다.
1
2
3
4
5
CRF 0 : 거의 무손실 → 파일 수십 GB / 시간
CRF 18 : 시각적 무손실 → 고품질 아카이빙
CRF 23 : 기본값 → 눈에 잘 안 띄는 손실, 스트리밍 배포 적당
CRF 28 : 모바일, 저용량 배포
CRF 35+ : 화질 뭉개짐 눈에 띔 → 미리보기, 테스트용
CRF의 특징은 목표 품질을 고정한다는 거다. 움직임이 많고 복잡한 장면은 비트레이트를 자동으로 높이고, 정적이고 단순한 장면은 낮춘다. 그래서 화질이 일정하게 유지되면서 전체 파일 크기도 최적화된다.
고정 비트레이트(-b:v 5000k)와 비교하면 차이가 명확하다.
1
2
3
4
5
6
7
8
고정 비트레이트:
단순 장면 → 5000k 낭비 (필요 이상)
복잡 장면 → 5000k 부족 (화질 저하)
CRF 23:
단순 장면 → 자동으로 낮춤
복잡 장면 → 자동으로 높임
→ 화질 일정, 파일 크기 최적
배포용 영상에는 CRF를 쓰고, 라이브 스트리밍처럼 실시간으로 비트레이트를 맞춰야 하는 상황에서는 고정 비트레이트를 쓴다.
Preset — 속도와 압축률의 트레이드오프
preset은 인코더가 얼마나 열심히 탐색할지 결정한다.
인코더는 각 블록마다 “어떤 크기로 나누고, 어떤 방향으로 예측하고, 어떤 참조 프레임을 쓸지”를 결정해야 한다. 이 선택지가 수백 가지다.
ultrafast는 빠르게 몇 가지만 시도하고 고른다. veryslow는 가능한 모든 조합을 다 시도해서 가장 작게 만드는 답을 찾는다. 더 많이 시도할수록 시간이 걸리지만 파일이 더 작아진다.
1
2
3
4
5
6
ultrafast: ~30초 / 파일 800MB (같은 CRF 23, 10분 1080p 기준)
veryfast: ~1분 / 파일 600MB ← 라이브 스트리밍
fast: ~2분 / 파일 530MB ← 게임 녹화
medium: ~3분 / 파일 500MB ← 기본값
slow: ~6분 / 파일 460MB ← YouTube 업로드 권장
veryslow: ~15분 / 파일 420MB ← 아카이빙
선택 기준은 단순하다. 한 번만 인코딩하는 VOD 배포라면 slow나 veryslow로 파일을 최대한 줄이는 게 낫다. 실시간으로 계속 인코딩해야 하는 라이브라면 veryfast가 맞다. 게임 방송처럼 게임하면서 동시에 인코딩해야 한다면 fast 정도에서 CPU 여유를 남겨야 한다.
개발하면서 테스트 인코딩을 자주 해야 할 때는 ultrafast로 빠르게 결과만 확인하고, 최종 배포 전에 slow로 다시 인코딩하는 방식을 썼다.
Profile / Level — 기기 호환성 제어
Profile은 H.264가 어떤 기능을 쓸 수 있는지 정한다.
| Profile | B-Frame | CABAC | 압축률 | 대상 |
|---|---|---|---|---|
| Baseline | ❌ | ❌ | 낮음 | 구형 기기 |
| Main | ✅ | ✅ | 중간 | 일반 기기 |
| High | ✅ + 추가 기능 | ✅ | 높음 | PC·스마트TV |
대부분의 경우 High를 쓰면 된다. 2012년 이후 기기는 거의 다 High를 지원한다. 구형 스마트폰이나 구형 TV까지 지원해야 한다면 Main이나 Baseline으로 낮춰야 한다.
Level은 해상도와 fps 조합의 한계를 정한다.
1
2
3
4
5
Level 3.1 → 720p 30fps
Level 4.0 → 1080p 30fps
Level 4.2 → 1080p 60fps ← YouTube 권장
Level 5.0 → 4K 30fps
Level 5.1 → 4K 60fps
기기가 지원하는 Level을 넘기면 재생이 안 되거나 끊긴다. 모바일에서만 안 된다는 제보가 오면 Level을 낮추거나 pix_fmt를 yuv420p로 바꾸는 것부터 시도해봤다.
1
2
3
4
5
6
7
# 범용 재인코딩 (호환성 문제 발생 시)
ffmpeg -i problem.mp4 \
-c:v libx264 \
-profile:v high \
-level 4.0 \
-pix_fmt yuv420p \
fixed.mp4
FFmpeg 목적별 설정 모음
이론은 이해했는데 실제로 어떻게 쓰는지가 중요하다. 목적별로 정리했다.
YouTube 업로드 권장 설정
1
2
3
4
5
6
7
8
9
10
ffmpeg -i input.mov \
-c:v libx264 \
-crf 23 \ # 품질 (18~28 실용 범위)
-preset slow \ # 한 번만 하니까 시간 투자
-profile:v high \ # 최고 압축 효율
-level 4.2 \ # 1080p 60fps 기준
-pix_fmt yuv420p \ # 브라우저 호환 필수
-c:a aac -b:a 192k \ # 오디오
-movflags +faststart \ # 다운로드 중 스트리밍 가능
output.mp4
-movflags +faststart는 MP4 메타데이터를 파일 앞으로 옮기는 옵션이다. 기본적으로 메타데이터가 파일 끝에 있어서, 웹에서 전체를 다운로드해야 재생이 시작된다. faststart를 붙이면 다운로드 중에도 바로 재생된다. 처음에 이걸 몰라서 웹 플레이어에서 재생이 느리게 시작되는 원인을 한참 찾았다.
라이브 스트리밍 (Twitch, YouTube Live)
1
2
3
4
5
6
7
8
ffmpeg -i input \
-c:v libx264 \
-b:v 6000k \ # Twitch 최대 비트레이트
-preset veryfast \ # 실시간 처리 필수
-tune zerolatency \ # B-Frame 비활성화, 지연 최소화
-g 60 \ # 2초마다 키프레임 (Twitch 요구사항)
-c:a aac -b:a 128k \
-f flv rtmp://live.twitch.tv/...
라이브는 CRF 대신 고정 비트레이트를 쓴다. 플랫폼마다 허용 비트레이트 한도가 있어서 그 안에서 맞춰야 하기 때문이다.
고품질 아카이빙 (원본 보관)
1
2
3
4
5
6
ffmpeg -i input.mov \
-c:v libx264 \
-crf 18 \ # 시각적 무손실에 가까운 품질
-preset veryslow \ # 한 번만 하니까 시간 최대한 투자
-pix_fmt yuv420p \
archive.mp4
빠른 테스트 인코딩
1
2
3
4
5
6
ffmpeg -i input.mov \
-c:v libx264 \
-crf 35 \ # 화질보다 속도 우선
-preset ultrafast \
-pix_fmt yuv420p \
test.mp4
인코딩 결과 검증
인코딩 후에는 꼭 확인해보는 게 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
# 코덱, Profile, Level, 픽셀 포맷, 비트레이트 한 번에
ffprobe -v error -select_streams v:0 \
-show_entries stream=codec_name,profile,level,pix_fmt,bit_rate,r_frame_rate \
-of default=noprint_wrappers=1 output.mp4
# 출력 예시:
# codec_name=h264
# profile=High
# level=42 (= Level 4.2)
# pix_fmt=yuv420p
# bit_rate=8500000 (= 8.5 Mbps)
# r_frame_rate=30/1
비트레이트가 예상보다 너무 높으면 CRF를 올리거나 preset을 느리게 해서 재인코딩한다. 너무 낮아서 화질이 나쁘면 CRF를 낮춘다.
마무리
스트리밍 프로토콜 공부할 때는 “영상을 잘게 쪼개서 전송한다”는 수준에서 넘어갔는데, 코덱까지 파고나니 퍼즐이 맞춰지는 느낌이었다.
HLS·DASH·WebRTC가 어떻게 전송하는지와, H.264가 그 안에 데이터를 어떻게 압축하는지를 같이 이해하고 나면 비트레이트 숫자나 GOP 설정이 왜 그렇게 정해지는지 이제 감이 온다.
YUV 변환부터 DCT, 양자화, 모션 예측, CABAC까지 각각은 단순한 아이디어인데 그게 쌓여서 671 GB를 4 GB로 만든다는 게 여전히 인상적이다. 눈이 못 느끼는 걸 버린다는 원칙 하나가 이 모든 걸 가능하게 한다.
다음은 H.265와 AV1을 비교할 예정이다. H.264가 MPEG-2 대비 2배라면, H.265는 H.264 대비 또 2배다. YouTube가 VP9에서 AV1으로 전환하는 이유도 정리해볼 생각이다.