YouTube는 왜 AV1을 골랐나 — 코덱 선택의 트레이드오프
지난번 H.264 포스트 마지막에 “다음은 H.265와 AV1을 비교할 예정”이라고 써놨는데, 막상 파보니 생각보다 이야기가 복잡했다.
단순히 “더 최신 코덱이 더 좋다”가 아니었다. H.265는 압축률은 좋은데 라이선스가 발목을 잡았고, AV1은 무료인데 인코딩이 너무 느려서 실무에서 바로 못 썼다. 왜 유튜브가 굳이 AV1을 골랐는지, 그리고 오디오는 왜 별개로 Opus라는 걸 또 쓰는지 이번에 제대로 정리했다.
H.265 (HEVC) — 압축률은 잡았는데 라이선스가 발목을 잡았다
H.264 다음 세대로 2013년에 ITU-T와 MPEG이 공동 표준화한 코덱이다. 공식 명칭은 H.265 또는 HEVC(High Efficiency Video Coding)다. 목표는 명확했다. 같은 화질을 H.264 대비 절반 비트레이트로 담는 것.
이게 어떻게 가능했는지 뜯어보면, H.264에서 이미 봤던 개념들(블록 분할, 예측, DCT, CABAC)을 그대로 가져가되 각 단계를 더 정교하게 다듬었다는 걸 알 수 있다. 완전히 새로운 방식이 아니라 “기존 방식을 더 세밀하게” 만든 코덱이다.
CTU — 매크로블록보다 유연한 단위
H.264는 16×16 매크로블록 고정이었다. 블록 크기를 4×4까지 쪼갤 수는 있었지만, 시작점 자체가 16×16으로 고정돼 있었다. H.265는 여기서 한 단계 더 나갔다.
CTU(Coding Tree Unit)는 최대 64×64 크기다. 그리고 이 블록을 필요하면 재귀적으로 4등분해서 32×32, 16×16, 8×8까지 쪼갤 수 있다. 쿼드트리(Quad-tree) 구조다.
1
2
3
4
5
6
64×64 CTU
├─ 단순한 배경(하늘) → 그대로 64×64 사용
└─ 복잡한 영역(나뭇잎) → 4등분
├─ 32×32
│ └─ 다시 필요하면 4등분 → 16×16 → 8×8
└─ ...
H.264는 최대가 16×16이었는데 H.265는 최대가 64×64다. 넓은 단색 영역이면 큰 블록 하나로 끝내니까 그만큼 오버헤드(블록마다 붙는 헤더 정보)가 줄어든다. 반대로 세밀한 영역은 8×8까지 쪼개서 디테일을 살린다. 유연성이 늘어난 만큼 압축 효율도 올라갔다.

CU / PU / TU — CTU 안에서도 역할이 나뉜다
CTU 하나를 쪼개는 것도 사실 한 단계가 아니다. H.265는 CTU 내부를 세 가지 단위로 다시 나눈다. 처음 이 세 개를 봤을 때 다 비슷해 보여서 헷갈렸는데, 각자 역할이 다르다.
- CU(Coding Unit): “이 블록을 인트라로 예측할지 인터로 예측할지”를 결정하는 단위. CTU를 쿼드트리로 쪼갠 결과가 곧 CU다.
- PU(Prediction Unit): 실제 예측(모션 벡터 or 인트라 방향)이 적용되는 단위. CU 하나가 PU 여러 개로 나뉠 수도 있다. 예를 들어 화면 절반은 배경, 절반은 움직이는 물체면 PU를 둘로 쪼개서 각각 다른 모션 벡터를 적용한다.
- TU(Transform Unit): DCT(정확히는 H.265에서 DST도 섞어 쓴다)가 실제로 적용되는 단위. 예측 오차를 주파수 변환할 때 이 단위로 쪼갠다.
1
2
3
4
CTU (64×64)
└─ CU (예측 방식 결정 단위, 8×8~64×64)
└─ PU (실제 예측 적용 단위)
└─ TU (DCT 변환 적용 단위, 4×4~32×32)
정리하면서 “CU는 결정, PU는 실행(예측), TU는 실행(변환)”이라고 역할을 나눠서 외우니까 훨씬 헷갈리지 않았다.
35방향 예측과 Merge / Skip 모드
인트라 예측도 더 정교해졌다. H.264는 9가지 방향이었는데 H.265는 35가지다. 예측 방향이 세밀해질수록 오차가 작아지고, 오차가 작을수록 저장할 데이터가 줄어든다.
1
2
H.264: 9방향 (수직, 수평, DC, 대각선 6종)
H.265: 35방향 (수직/수평 기준 ±16단계씩 세분화 + DC + Planar)
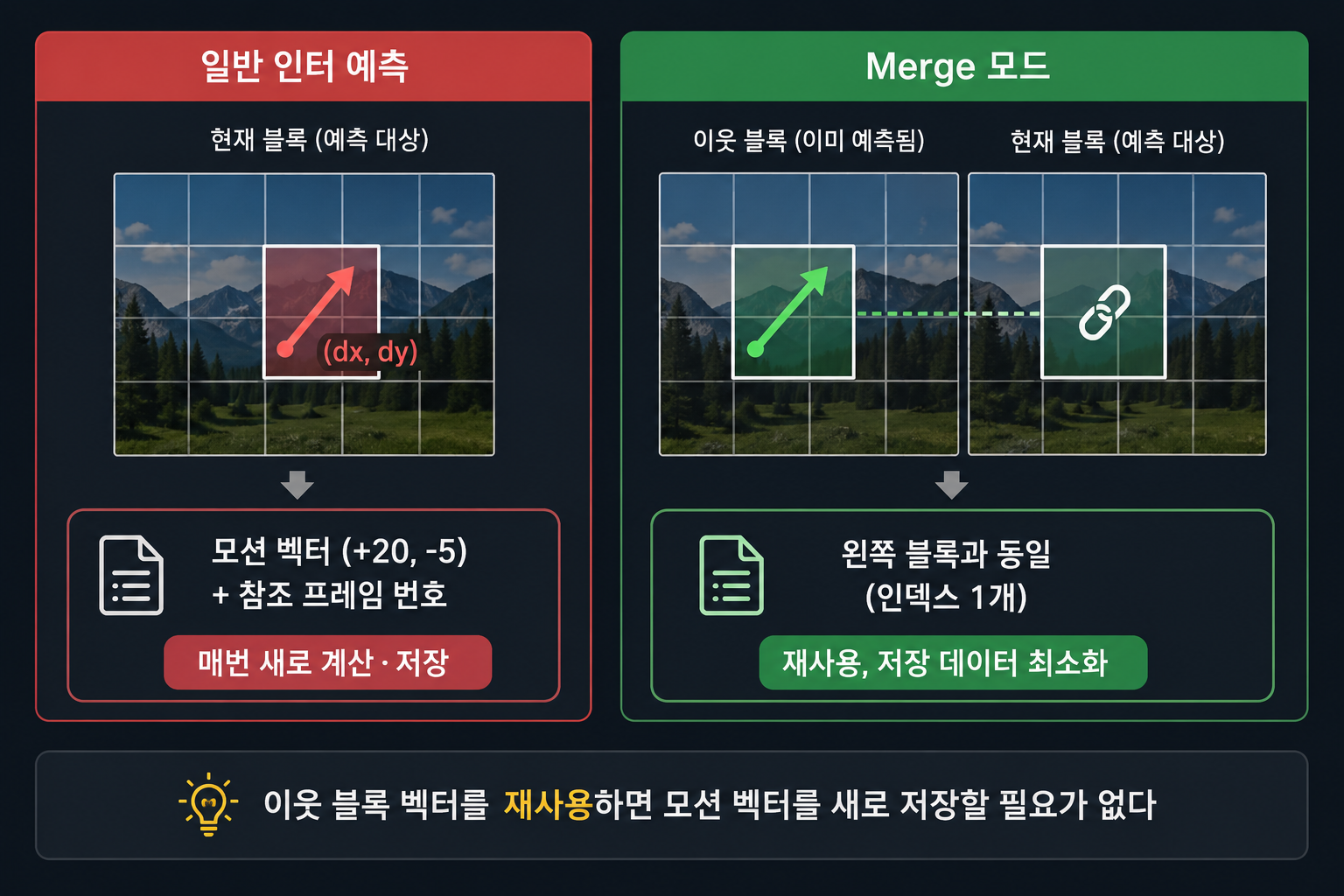
인터 예측 쪽에는 Merge 모드라는 게 새로 생겼다. 이웃 블록이 이미 계산해둔 모션 벡터를 그대로 가져다 쓰는 방식이다. 공이 화면 전체에서 같은 방향으로 움직이면 옆 블록 벡터를 복사만 하면 되니까, 모션 벡터를 새로 계산해서 저장할 필요가 없어진다.
1
2
일반 인터 예측: 모션 벡터 (dx, dy) + 참조 프레임 번호 저장
Merge 모드: "왼쪽 블록과 동일" 이라는 인덱스 하나만 저장
아예 움직임이 없는 블록은 Skip 모드로 처리한다. 모션 벡터도 예측 오차도 저장하지 않고, “이 블록은 이전 프레임과 완전히 동일하다”는 플래그 하나만 남긴다. 뉴스 앵커 영상에서 배경 스튜디오 영역이 딱 이 케이스다.
이 부분 보면서 “결국 압축이라는 게 반복되는 패턴을 얼마나 영리하게 재사용하냐의 싸움이구나” 싶었다. H.264에서 배운 예측 개념을 H.265가 한 단계 더 세분화한 느낌이다.
Tile과 WPP — 멀티코어를 쓰기 위한 설계
H.264는 설계될 당시(2003년) 멀티코어 CPU가 지금처럼 흔하지 않았다. 그래서 프레임 하나를 여러 코어가 나눠서 인코딩하는 걸 염두에 두지 않았다.
H.265는 처음부터 병렬 처리를 고려해서 설계됐다. 두 가지 방식이 있다.
- Tile: 프레임을 격자 모양으로 나눠서 각 타일을 독립적인 코어가 처리한다. 타일끼리는 서로 참조하지 않아서 완전히 독립적으로 돌릴 수 있다.
- WPP(Wavefront Parallel Processing): 프레임을 가로 줄(row) 단위로 나누되, 각 줄이 바로 위 줄의 처리가 살짝 앞서가면 그 뒤를 따라가면서 처리한다. 완전히 독립적인 Tile보다 압축 효율은 조금 더 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
Tile 방식:
┌────┬────┐
│코어1│코어2│ → 서로 독립, 빠르지만 경계에서 압축 효율 약간 손해
├────┼────┤
│코어3│코어4│
└────┴────┘
WPP 방식:
Row 0 ████████████ (코어 1)
Row 1 ███████████ (코어 2, Row 0보다 2블록 늦게 시작)
Row 2 ██████████ (코어 3, Row 1보다 2블록 늦게 시작)
→ 대각선으로 물결(wavefront)치듯 진행, 압축 효율 손해 적음
이 옵션들 덕분에 4K, 8K처럼 프레임이 커져도 멀티코어 서버에서 인코딩 시간을 단축할 수 있다. 실무에서 트랜스코딩 서버를 운영한다면 코어 수에 맞춰 Tile/WPP를 켜는 게 기본이라고 한다.
그런데 왜 못 썼나 — 라이선스 지옥
압축률만 보면 H.265를 안 쓸 이유가 없다. 그런데 실무에서 H.265 채택이 생각보다 더뎠다. 이유는 특허다.
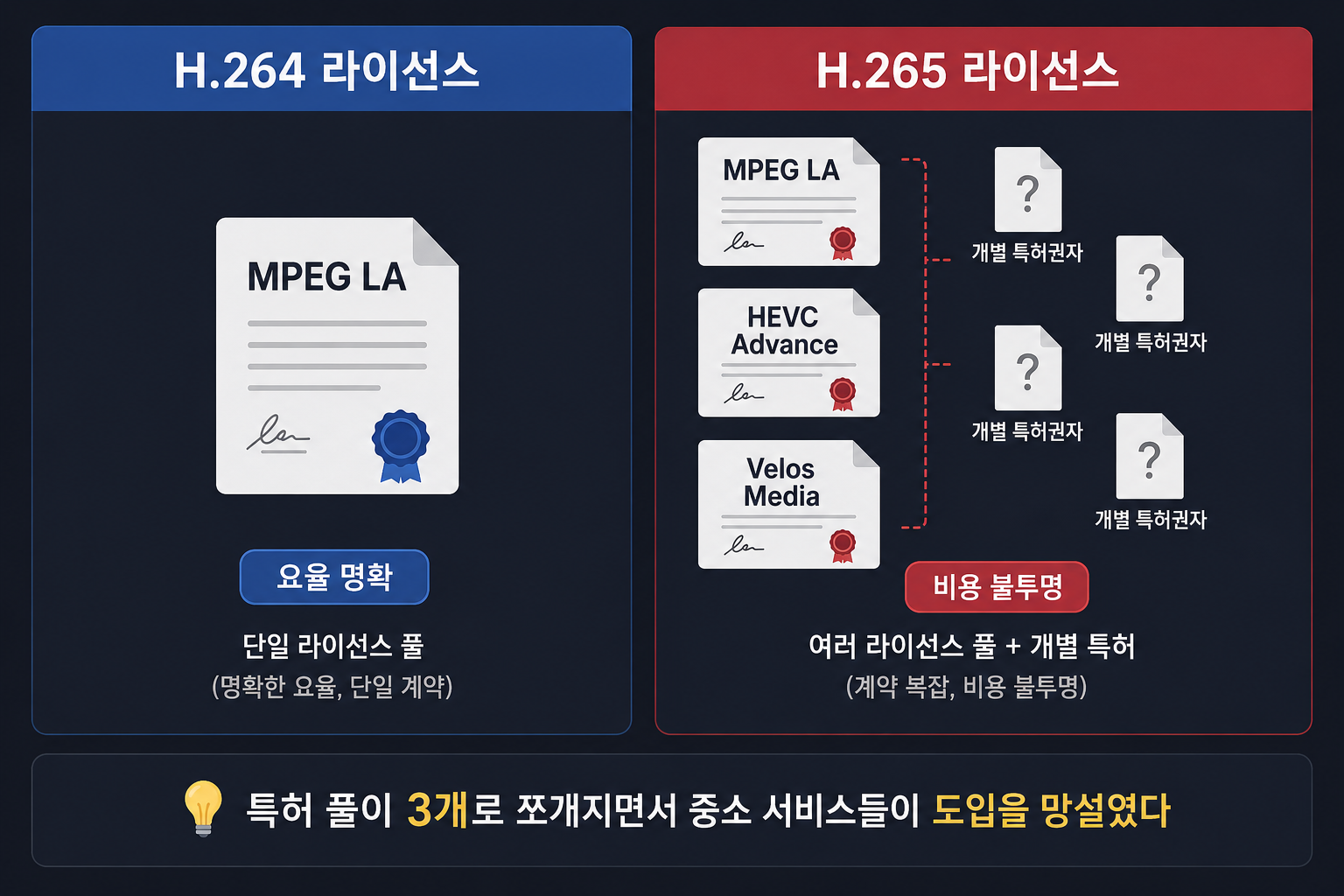
H.264는 라이선스 관리 주체가 MPEG LA 한 곳이었다. H.265는 MPEG LA + HEVC Advance + Velos Media, 세 개의 특허 풀로 쪼개졌다. 게다가 이 풀에 참여하지 않은 개별 특허권자들도 있어서 정확히 얼마를 누구한테 내야 하는지조차 불투명했다.
1
2
3
4
5
6
7
8
9
H.264 라이선스 구조:
MPEG LA 한 곳 → 요율 비교적 명확
H.265 라이선스 구조:
MPEG LA (특허 풀 1)
+ HEVC Advance (특허 풀 2)
+ Velos Media (특허 풀 3)
+ 개별 특허권자 다수 (풀에 미참여)
→ 전체 비용을 사전에 정확히 계산하기 어려움
Netflix나 Apple처럼 큰 회사는 라이선스 비용을 감당하고 H.265를 쓴다. 하지만 중소 서비스는 “얼마가 청구될지 모른다”는 리스크 하나로 도입을 망설였다. 이게 나중에 AV1이 나오는 배경이 된다.
CRF 값 매핑과 Apple 태그 문제
기기 호환성 이슈도 있었다. Apple 생태계에서 H.265를 쓰려면 컨테이너에 코덱 태그를 명시해야 한다.
1
2
3
4
5
6
7
# Apple 기기 호환 H.265 인코딩
ffmpeg -i input.mov \
-c:v libx265 \
-crf 28 \ # H.264 CRF 23과 비슷한 체감 화질
-tag:v hvc1 \ # 이게 없으면 iOS/macOS에서 재생 안 됨
-c:a aac -b:a 192k \
output.mp4
-tag:v hvc1을 빼먹으면 인코딩은 성공하는데 iPhone에서 그냥 재생이 안 된다. 처음 이거 겪었을 때 코덱 자체가 문제인 줄 알고 한참 삽질했는데, 알고 보니 태그 하나 때문이었다. 기본 태그(hev1)로 저장되면 macOS/iOS 플레이어가 이걸 인식하지 못하고, 반드시 애플이 정의한 hvc1 태그가 붙어야 재생이 된다.
CRF 값도 H.264와 그대로 비교하면 안 된다. 같은 CRF 숫자여도 코덱마다 양자화 스케일이 다르게 설계됐기 때문이다.
1
2
3
4
체감 화질이 비슷한 CRF 매핑:
H.264 CRF 18 ≈ H.265 CRF 23
H.264 CRF 23 ≈ H.265 CRF 28 (둘 다 각 코덱의 기본값)
H.264 CRF 28 ≈ H.265 CRF 32
실제로 H.264 CRF 23 설정 그대로 H.265에 적용했다가 “왜 파일이 예상보다 훨씬 작지?” 하고 놀란 적이 있다. 화질을 확인해보니 눈에 띄게 나빠져 있었다. CRF 숫자를 코덱 간에 그대로 복붙하면 안 된다는 걸 이때 배웠다.
Apple의 실제 채택 사례
이론만 보면 라이선스 때문에 다들 꺼릴 것 같지만, Apple은 2017년 iPhone 8부터 카메라 기본 촬영 코덱을 H.265로 바꿨다. 자체 생태계(칩·OS·앱)를 다 통제하니까 라이선스 비용을 감당할 여력이 있었고, 저장 공간을 절반으로 줄이는 이득이 훨씬 컸기 때문이다.
반면 웹 서비스 대부분은 여전히 H.264를 기본으로 깔고, H.265는 지원 기기에 한해서만 옵션으로 제공하는 식으로 타협했다.
AV1 — 라이선스 문제를 근본적으로 없앤 코덱
H.265의 라이선스 문제가 불거지면서 2018년에 등장한 게 AV1이다. AOM(Alliance for Open Media)이라는 연합이 만들었는데, 참여 기업 면면이 화려하다. Google, Netflix, Amazon, Apple, Intel, ARM까지 다 들어가 있다.
왜 이렇게 큰 회사들이 다 뭉쳤나
이 조합을 보고 좀 놀랐다. 서로 경쟁 관계인 회사들이 왜 한 코덱에 다 같이 투자했을까 싶었는데, 답은 간단했다. 다들 스트리밍 비용을 줄이고 싶었고, 다들 특허 리스크에서 자유로워지고 싶었던 거다. 로열티 프리라는 목표 하나로 이해관계가 맞아떨어진 셈이다.
H.265 특허 풀이 쪼개지면서 생긴 불확실성을 다들 겪었으니, “그럼 우리가 다 같이 돈을 모아서 완전히 무료인 코덱을 만들고, 특허 소송이 걸리면 다 같이 방어하자”는 컨소시엄 구조를 만든 거다.
VP9 — AV1 이전에 이미 시도됐던 로열티 프리 코덱
사실 AV1이 처음으로 로열티 프리를 시도한 코덱은 아니다. 2013년 Google이 On2 Technologies를 인수하면서 만든 VP9이 먼저였다. VP9도 이미 무료였고, YouTube가 채택하면서 널리 쓰였다.
VP9은 슈퍼블록 64×64, 8개의 참조 프레임을 지원했다. H.265와 비슷한 시기에 비슷한 목표(로열티 프리 + 고압축)로 나온 코덱인데, 다만 Google 혼자 주도한 프로젝트라서 업계 전체의 힘을 모으지는 못했다. AV1은 이 VP9의 기술 기반 위에 AOM이라는 더 큰 연합을 만들어서 낸 후속작에 가깝다.
1
2
3
4
5
VP9 (2013, Google) → AV1 (2018, AOM 연합)
슈퍼블록 64×64 슈퍼블록 128×128
참조 프레임 8개 참조 프레임 7슬롯 + 합성 예측
인트라 예측 10방향 인트라 예측 56방향
단일 기업 주도 12개+ 기업 컨소시엄
슈퍼블록 128×128과 합성 예측
AV1의 기본 처리 단위는 슈퍼블록 128×128이다. H.265 CTU(64×64)보다, VP9 슈퍼블록(64×64)보다도 한 단계 더 크다. 그만큼 넓은 단색 영역을 더 효율적으로 처리한다.
인트라 예측 방향도 56가지로 늘었다. H.265의 35가지보다 더 세밀하다.
인터 예측 쪽에서는 합성 예측(Compound Prediction)이라는 개념이 강화됐다. H.265의 B-Frame이 앞뒤 두 프레임을 참조했다면, AV1은 참조 프레임 슬롯 7개를 두고 이 중 여러 개를 조합해서 예측한다. 여러 참조 프레임의 가중 평균을 내거나, 마스크를 씌워서 프레임의 특정 영역만 다른 참조를 쓰는 것도 가능하다. 카메라 팬(pan)처럼 화면 전체가 이동하는 장면에서 특히 효율이 좋아졌다.

필름 그레인 합성 — 노이즈를 압축하지 않고 재생성한다
개인적으로 제일 흥미로웠던 기능은 필름 그레인 합성(Film Grain Synthesis)이다. 영화 원본에는 필름 입자 노이즈가 있는데, 이 노이즈는 무작위성이 강해서 압축이 아주 안 된다. DCT를 아무리 잘 걸어도 무작위 노이즈는 저주파/고주파로 깔끔하게 나뉘지 않으니까 양자화로 버릴 수도 없다.
그런데 어차피 사람 눈에는 “그런 느낌”만 있으면 되지 노이즈 하나하나가 원본과 완전히 똑같을 필요는 없다.
그래서 AV1은 노이즈 픽셀 자체를 저장하는 대신 노이즈의 통계적 패턴(강도, 분포, 색상 채널별 상관관계)만 인코딩 시점에 분석해서 파라미터 몇 개로 저장해두고, 재생할 때 디코더가 그 파라미터를 기준으로 노이즈를 새로 생성해서 화면에 입힌다.
1
2
3
4
5
기존 방식: 노이즈 포함 원본 영상 → DCT/양자화 → 노이즈도 그대로 압축 시도 (비효율)
AV1 방식: 노이즈 제거한 깨끗한 영상 → 압축 (효율적)
+ 노이즈 파라미터(강도, 분포) 몇 바이트만 별도 저장
→ 재생 시 파라미터 기반으로 노이즈 재생성해서 합성
원본과 완전히 같은 노이즈는 아니지만 체감 품질은 거의 차이가 없다. 노이즈를 압축하는 게 아니라 “노이즈 만드는 법”만 압축한다는 발상이 신선했다. Netflix가 이 기능을 특히 적극적으로 쓰는데, 영화 콘텐츠 다수가 필름 그레인이 있는 소스라서 그렇다.

그런데 인코딩이 너무 느리다
AV1의 진짜 문제는 압축률이 아니라 속도였다. 참조 인코더인 libaom으로 인코딩하면 H.264보다 수십 배 느리다. 실무에서 못 쓸 수준이다.
이 문제를 해결하려고 Netflix와 Meta가 별도로 SVT-AV1(libsvtav1)이라는 인코더를 만들었다. libaom 대비 5~10배 빠르다. 지금은 실무에서 AV1을 쓴다고 하면 거의 다 SVT-AV1을 쓴다고 보면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# libaom (느림, 압축 효율 최고)
ffmpeg -i input.mov \
-c:v libaom-av1 \
-crf 30 -b:v 0 \ # CRF 모드는 -b:v 0을 반드시 같이 써야 함
-cpu-used 4 \ # 0(가장 느림·고효율) ~ 8(가장 빠름)
output.mp4
# SVT-AV1 (실무에서 주로 씀)
ffmpeg -i input.mov \
-c:v libsvtav1 \
-crf 30 \
-preset 8 \ # 0(가장 느림) ~ 13(가장 빠름)
output.mp4
-b:v 0을 안 붙이면 -crf가 무시되고 인코더가 기본 비트레이트 모드로 동작해버린다. 처음에 CRF 값을 바꿔도 파일 크기가 안 변해서 한참 헤맸는데, 이 옵션 하나가 원인이었다.
체감 인코딩 속도 차이를 정리하면 이렇다.
1
2
3
4
5
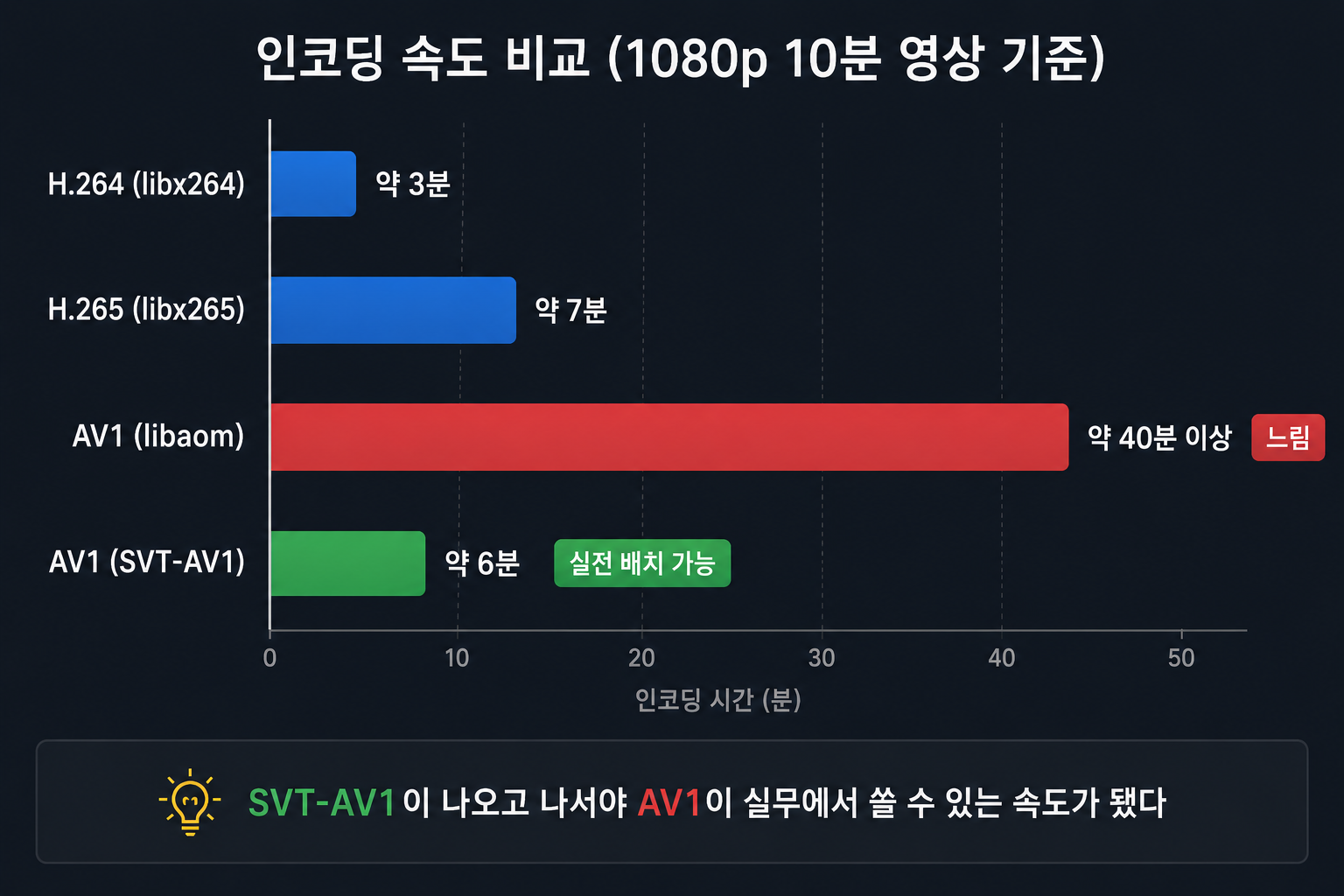
같은 1080p 10분 영상, CRF 30 기준 (체감 비교용 수치):
H.264 (libx264, medium) : 약 3분
H.265 (libx265, medium) : 약 7분
AV1 (libaom, cpu-used 4) : 약 40분 이상
AV1 (SVT-AV1, preset 8) : 약 6분
libaom 그대로 실무에 쓰면 인코딩 큐가 감당이 안 된다. SVT-AV1이 나오고 나서야 AV1이 실전 배치가 가능한 수준이 됐다.
Safari 문제와 fallback
AV1은 아직 모든 브라우저가 지원하지 않는다. Safari 17 미만은 AV1을 재생 못 한다. 그래서 웹에서 쓰려면 fallback이 필요하다.
1
2
3
4
5
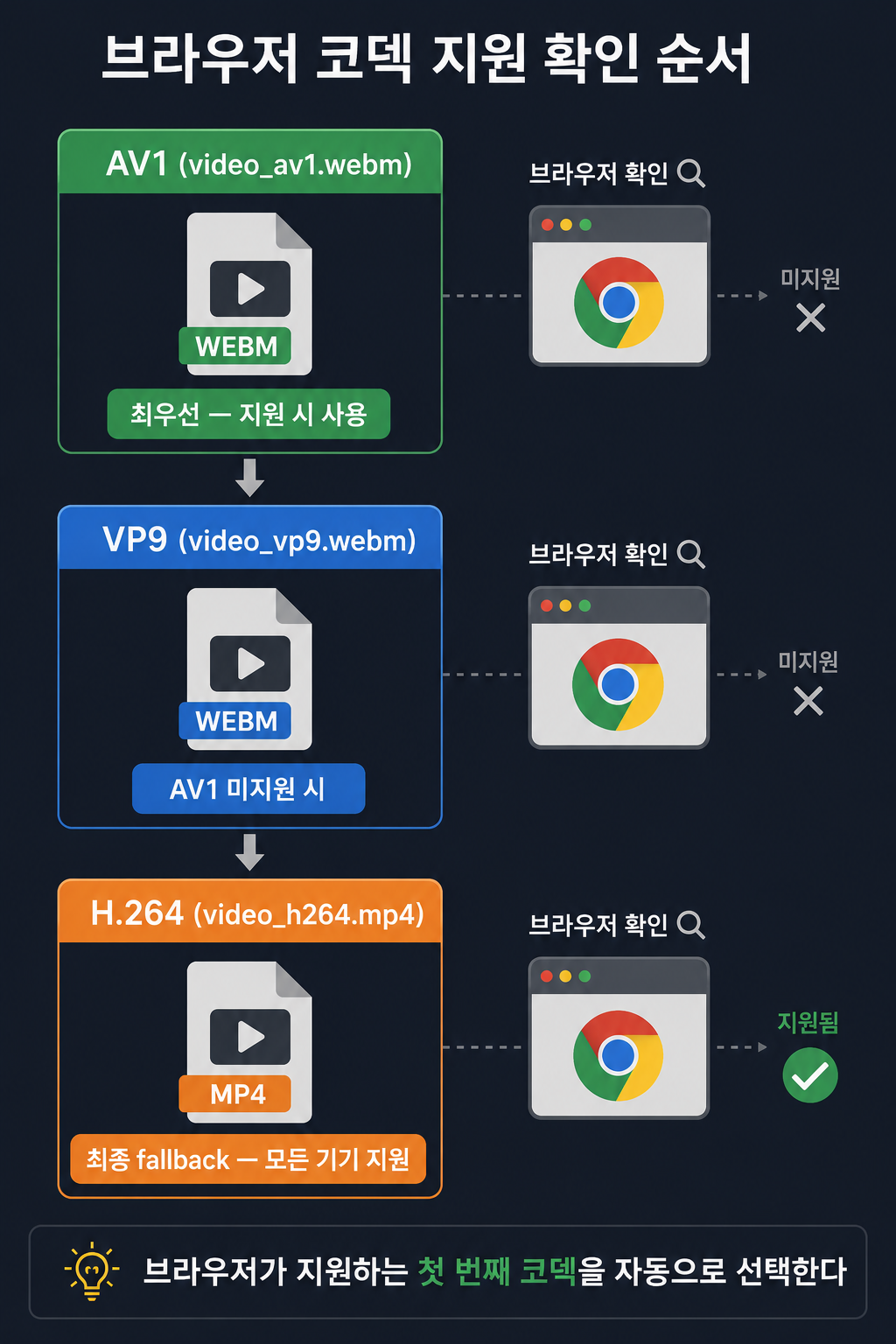
<video>
<source src="video_av1.webm" type="video/webm; codecs=av01.0.08M.08">
<source src="video_vp9.webm" type="video/webm; codecs=vp9">
<source src="video_h264.mp4" type="video/mp4">
</video>
브라우저는 <source> 태그를 위에서부터 순서대로 확인해서 재생 가능한 첫 번째 소스를 고른다. AV1을 지원하면 AV1을, 안 되면 VP9을, 그것도 안 되면 H.264를 쓰는 3단 fallback 구조다.
유튜브가 실제로 이렇게 한다. AV1을 지원하는 기기·브라우저에는 AV1을, 안 되는 곳에는 VP9이나 H.264를 내려준다. 유튜브 정도 규모의 트래픽이면 코덱 하나 바꿀 때 절감되는 대역폭이 어마어마할 텐데, 그 이득 때문에 여러 코덱을 동시에 관리하는 복잡함을 감수하는 거였다.
Opus vs AAC — 영상 코덱과 별개로 오디오도 골라야 한다
여기까지가 영상 압축 이야기다. 그런데 영상 안에는 오디오 트랙도 있고, 이건 완전히 다른 코덱을 쓴다. H.264/H.265/AV1과 별개로 오디오는 AAC나 Opus 중에서 고른다.
AAC — MP3의 정식 후계자
MP3를 만든 단체(MPEG)가 1997년에 낸 후속 코덱이다. 같은 음질을 MP3보다 30% 작은 용량으로 담는다. Apple이 iTunes에서 기본으로 채택하면서 사실상 업계 표준이 됐다.
동작 원리는 앞서 H.264에서 봤던 것과 똑같은 발상이다. 사람 귀가 큰 소리 직후에는 작은 소리를 잘 못 듣는다는 특성(심리음향 마스킹)을 이용해서, 어차피 안 들리는 주파수 성분을 버린다. 눈의 약점을 이용한 YUV 크로마 서브샘플링이랑 완전히 같은 원리라서, 이 부분 보면서 “압축이라는 게 결국 인간 감각의 한계를 파고드는 거구나” 싶었다.
1
2
3
4
5
6
7
8
9
10
11
12
AAC 인코딩 흐름:
PCM 원본
↓
MDCT (주파수 분해, 1024 샘플 기본 / 급변 구간 128 샘플)
↓
심리음향 모델 (마스킹 임계값 계산 → 안 들리는 주파수 식별)
↓
양자화 (마스킹 임계값 기준으로 비트 할당)
↓
Huffman 엔트로피 코딩
↓
AAC 비트스트림
Opus — 통화를 위해 태어난 코덱
AAC로는 부족한 영역이 있었다. 바로 실시간 음성통화다. AAC는 최소 프레임 크기가 1024 샘플이라 지연이 20ms 이상 깔린다. 스카이프 통화나 게임 보이스챗처럼 지연에 민감한 상황에는 안 맞는다.
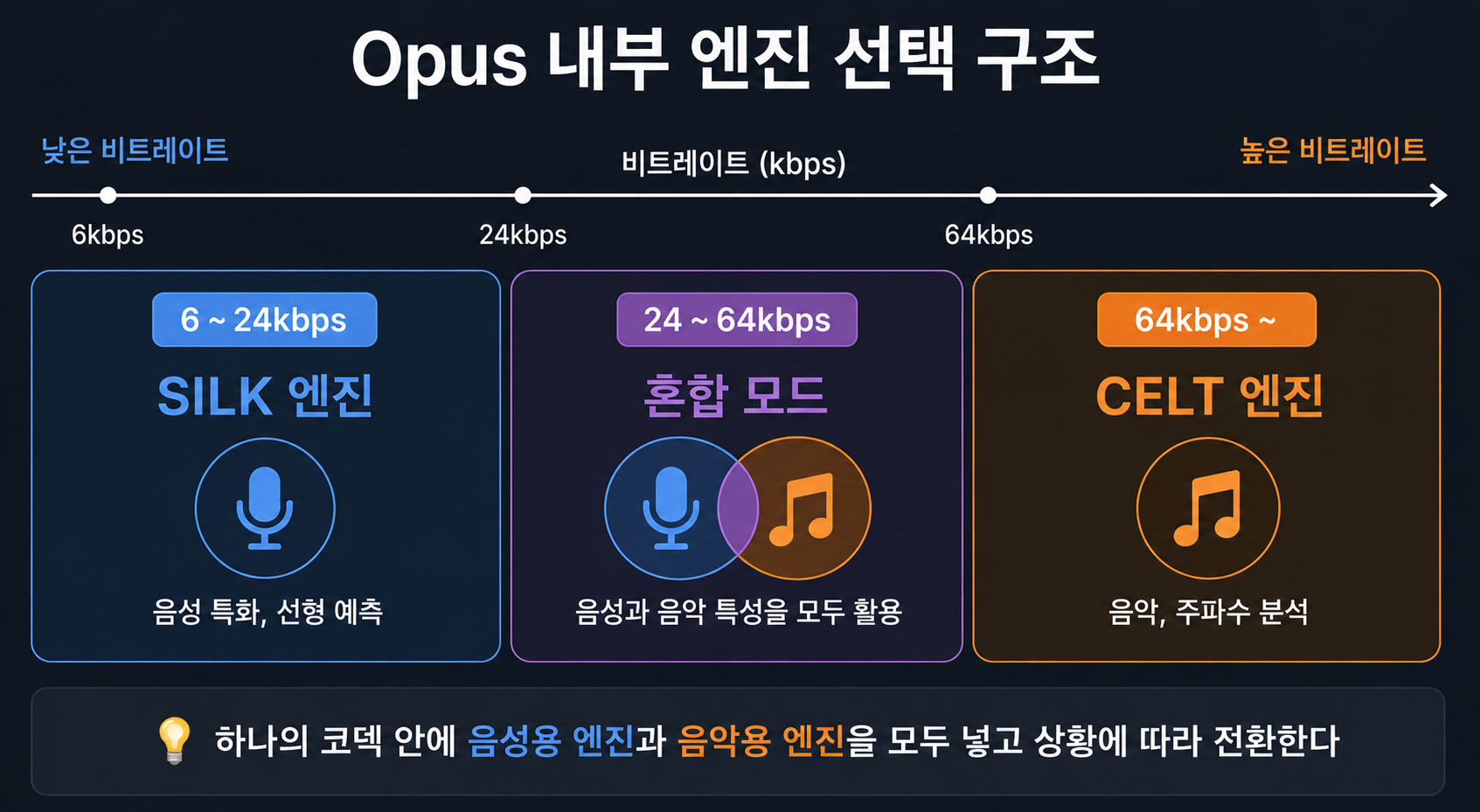
그래서 나온 게 Opus다. Skype의 음성 압축 기술(SILK)과 Xiph.Org의 음악 압축 기술(CELT)을 합쳐서 2012년 IETF 표준(RFC 6716)으로 정리했다. 완전히 무료라서 라이선스 걱정이 없고, 프레임 크기를 2.5ms까지 줄일 수 있어서 저지연에 최적화됐다.
1
2
3
4
Opus 내부 동작:
6~24kbps → SILK 엔진 (음성 특화, 이전 소리로 다음 소리 예측)
24~64kbps → 혼합 모드
64kbps+ → CELT 엔진 (음악, AAC와 비슷한 주파수 분석 방식)
비트레이트에 따라 내부 엔진이 자동으로 바뀐다는 게 재밌었다. 하나의 코덱 안에 음성용 엔진과 음악용 엔진을 둘 다 넣어놓고 상황 따라 골라 쓰는 구조다.
이게 WebRTC 표준 필수 코덱으로 지정되면서 Discord, Zoom, 대부분의 화상회의 서비스가 다 Opus를 쓴다.
1
2
3
4
5
6
7
8
9
# AAC — VOD, 음악 스트리밍
ffmpeg -i input.wav -c:a aac -b:a 192k output.m4a
# Opus — 실시간 통화, WebRTC
ffmpeg -i input.wav \
-c:a libopus \
-b:a 64k \
-application voip \ # audio(음악) | voip(통화) | lowdelay(초저지연)
output.opus
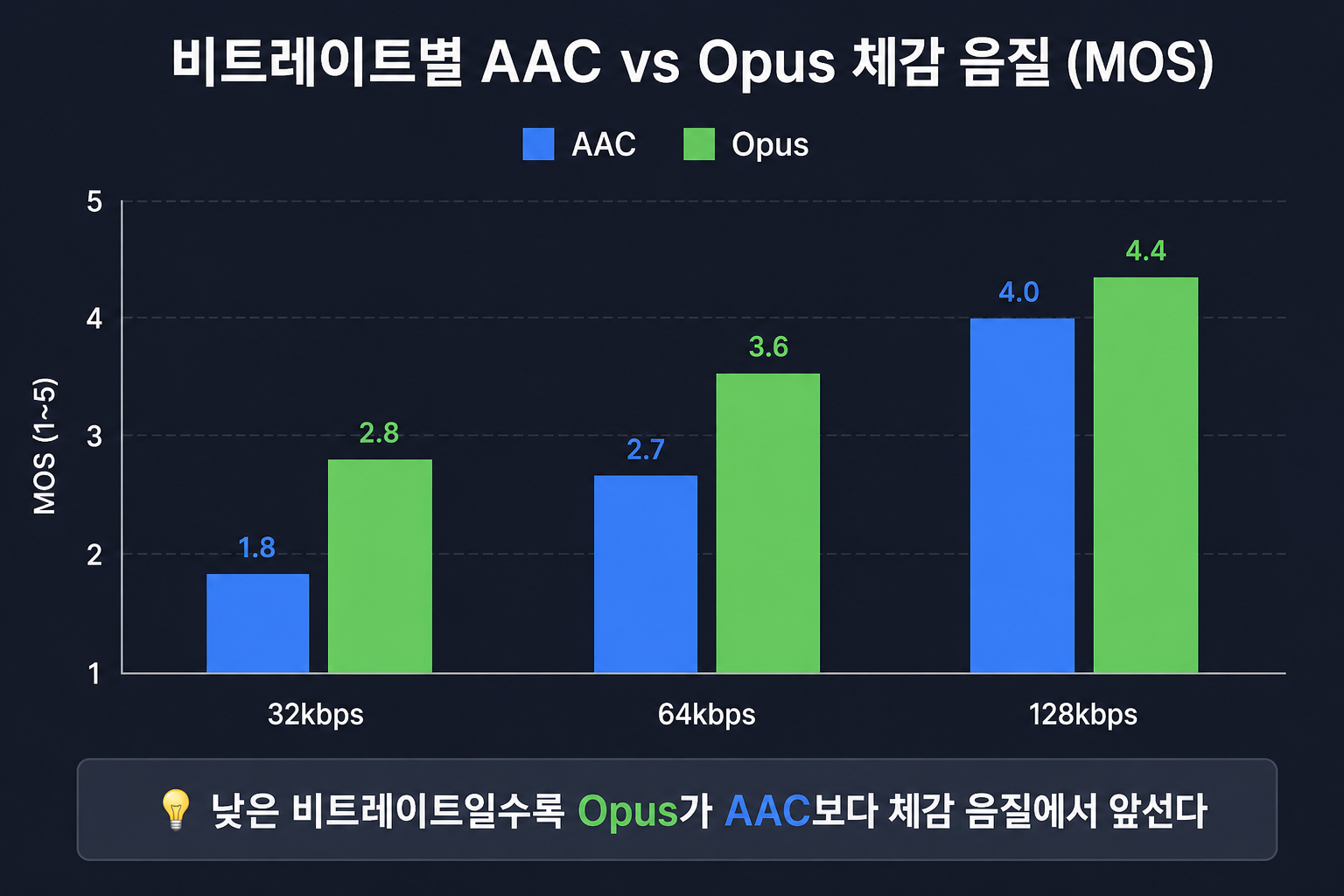
같은 체감 품질 기준으로 보면 Opus 64kbps가 AAC 128kbps랑 비슷하다. 저비트레이트에서는 Opus가 확실히 앞선다. 대신 하드웨어 디코딩 지원은 AAC가 훨씬 넓다. 그래서 유튜브는 영상 오디오에 AAC를 쓰고, 화상통화 서비스는 Opus를 쓰는 식으로 용도가 갈린다.
비트레이트별 체감 품질(MOS 기준) 비교표:
| 비트레이트 | AAC | Opus |
|---|---|---|
| 32kbps | 음질 저하 뚜렷 | 통화용으로 준수 |
| 64kbps | 보통 | FM 라디오 수준 |
| 128kbps | CD 음질에 근접 | AAC와 동급~약간 우수 |
세 코덱을 놓고 보면
정리하면서 느낀 건, “최신 코덱이 무조건 낫다”는 생각이 틀렸다는 거였다.
H.265는 압축률은 확실히 좋은데 라이선스가 발목을 잡아서 채택이 더뎠다. AV1은 라이선스 문제를 없앴지만 인코딩 속도가 발목을 잡아서 SVT-AV1 같은 별도 인코더가 나와야 했다. Opus는 압축률 경쟁이 아니라 아예 “지연”이라는 다른 축에서 AAC와 경쟁한다.
한눈에 비교:
| 항목 | H.264 | H.265 | AV1 | VP9 |
|---|---|---|---|---|
| 등장 연도 | 2003 | 2013 | 2018 | 2013 |
| 라이선스 | 단일 풀 | 3개 풀 (복잡) | 완전 무료 | 완전 무료 |
| 압축 효율 | 기준 | H.264 대비 ~50% | H.265 대비 ~30% 추가 | H.264 대비 ~40% |
| 인코딩 속도 | 빠름 | 중간 | 느림 (SVT로 개선) | 중간 |
| 기기 지원 | 거의 전부 | 2017년 이후 다수 | 최신 기기 위주 | 대부분 브라우저 |
결국 코덱 선택은 압축률 하나가 아니라 라이선스, 인코딩 속도, 기기 호환성, 지연시간을 다 같이 저울질하는 문제였다. 유튜브가 H.264·VP9·AV1을 동시에 서빙하는 것도 이 트레이드오프를 완전히 없앨 방법이 없어서 여러 코덱을 병행하는 거였구나 싶다.
다음은 VMAF·SSIM·PSNR로 화질을 숫자로 측정하는 법을 정리할 예정이다. 지금까지는 “화질이 좋다/나쁘다”를 감으로만 얘기했는데, 이제 이걸 수치로 검증하는 법을 배워볼 차례다.