당근 기술 블로그 — 처음 살펴본 서킷 브레이커와 SLA
멘토님이 당근 기술 블로그 링크를 보내주셨다. 피드시스템 안정성 향상기인데, 읽으면서 이름만 들어봤던 개념들이 실제로 어떻게 쓰이는지 처음 감이 왔다.
연쇄 장애 — 하나가 죽으면 왜 전체가 죽나
당근 피드에는 동네생활, 중고거래, 구인공고, 중고차, 부동산 등 여러 마이크로서비스가 붙어있다. 사용자가 피드를 열면 이 서비스들한테 동시에 요청해서 결과를 조합해 보여준다.
문제는 중고거래 서비스 하나가 느려지기 시작하면 피드 서비스가 응답을 기다리면서 스레드를 계속 점유한다는 거다. 요청이 쌓이고, 결국 피드 서비스도 같이 터진다.
1
2
3
4
중고거래 서비스 응답 지연
→ 피드 서비스 스레드 점유
→ 다른 사용자 요청도 대기
→ 피드 서비스 전체 마비
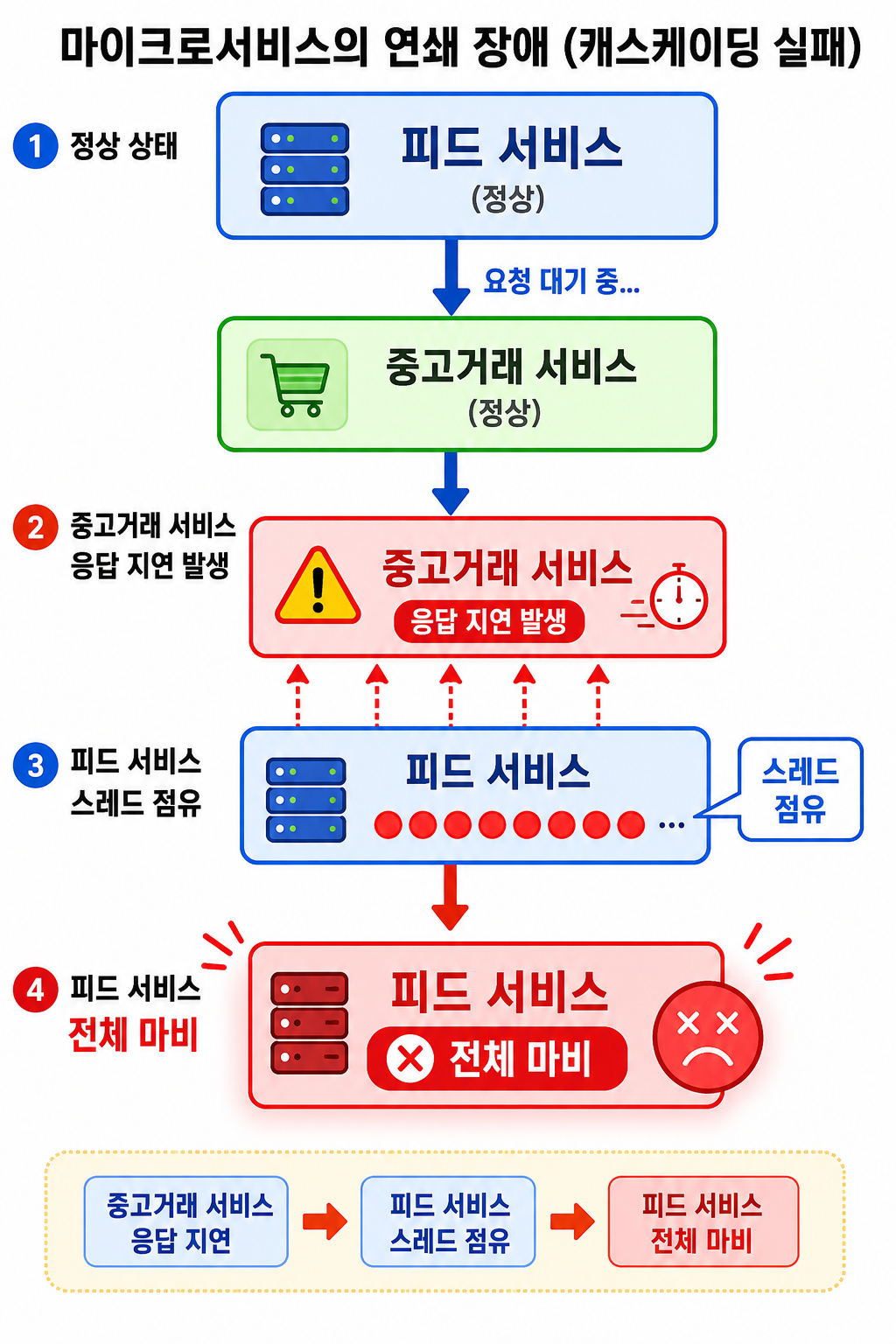
이걸 연쇄 장애(Cascading Failure)라고 부른다. 읽으면서 “당연한 거 아닌가?” 싶었는데, 생각해보면 이게 마이크로서비스 구조의 근본적인 취약점이었다. 모놀리식에선 내부 함수 호출이라 네트워크 장애 자체가 없으니까.
서킷 브레이커 — 실패를 빠르게 인정하는 설계
연쇄 장애를 막는 핵심 패턴이 서킷 브레이커(Circuit Breaker)다. 이름 그대로 전기 차단기에서 따왔다. 세 가지 상태를 오간다.
Closed (정상): 요청이 그냥 통과한다. 내부적으로 실패를 카운팅하고 있다.
Open (차단): 실패율이 임계값을 넘으면 전환된다. 의존 서비스한테 요청 자체를 안 보내고 즉시 에러를 반환한다.
Half-Open (탐색): Open 상태로 일정 시간이 지나면 “혹시 복구됐나?” 하고 소량 요청만 통과시킨다. 성공하면 Closed로, 실패하면 다시 Open으로.
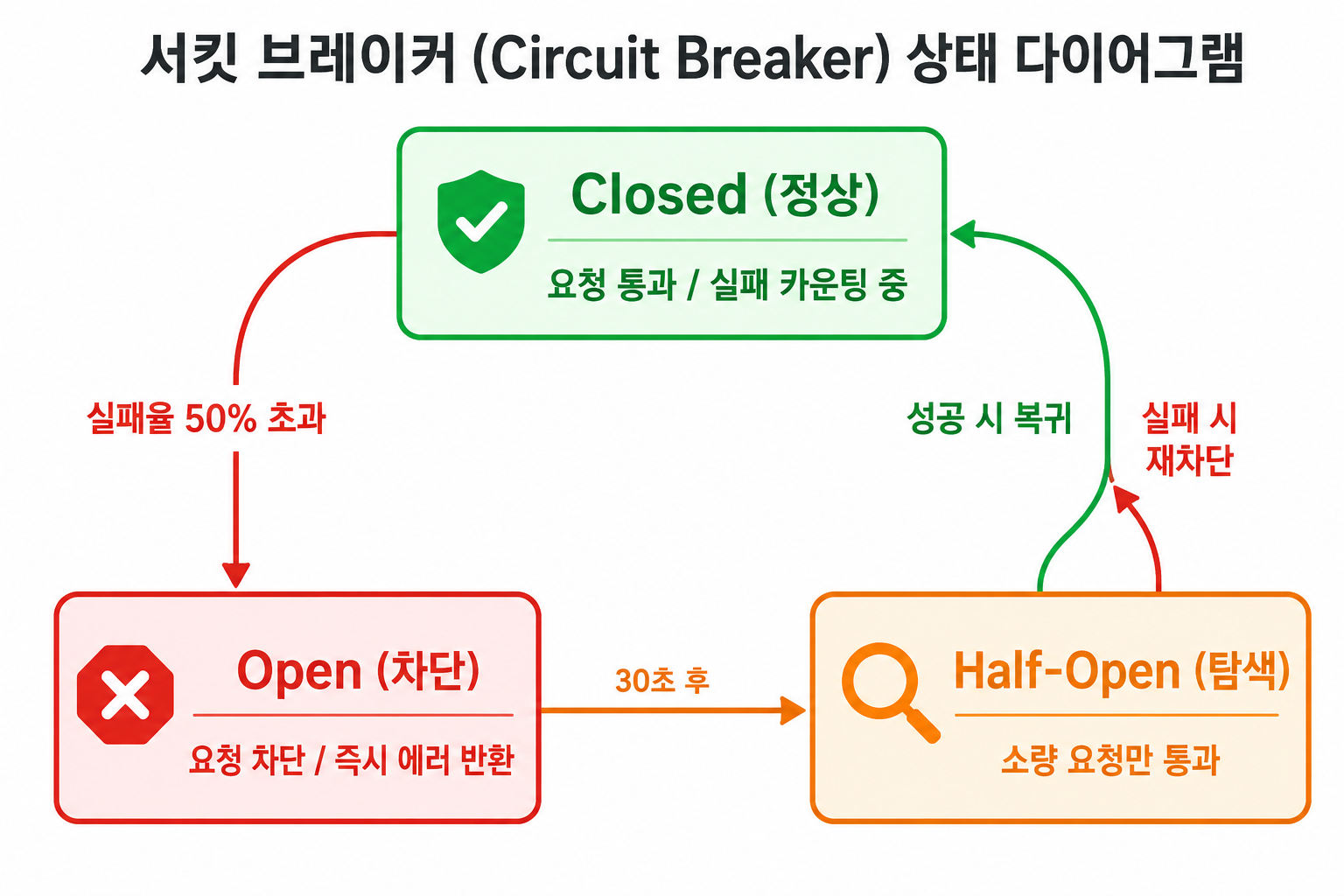
Spring에서는 Resilience4j로 구현한다.
1
2
3
4
5
6
7
8
9
10
11
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 실패율 50% 초과 시 Open
.waitDurationInOpenState(Duration.ofSeconds(30)) // 30초 후 Half-Open
.slidingWindowSize(10) // 최근 10개 요청 기준
.build();
try {
items = circuitBreaker.executeSupplier(() -> 중고거래서비스.getItems());
} catch (CallNotPermittedException e) {
items = Collections.emptyList(); // 중고거래 없이 피드 반환
}
핵심은 “실패를 기다리지 않는 것”이다. 어차피 실패할 요청에 자원 낭비하지 않고 빠르게 포기(fail fast)한 다음, 중고거래 없이도 피드를 보여주는 방향으로 간다. 이걸 Graceful Degradation이라고 부른다.
처음엔 “그냥 타임아웃 짧게 하면 되지 않나?” 싶었는데, 타임아웃은 매번 기다리는 거고 서킷 브레이커는 아예 요청을 안 보내는 거라 차이가 크다.
프로파일링 — 감이 아니라 측정으로
당근이 성능 최적화에서 강조한 게 “측정 먼저”였다. 느릴 것 같은 부분을 감으로 최적화하면 엉뚱한 데 시간 쓰는 경우가 많다. Go에서는 pprof로 CPU, 메모리 프로파일을 수집해서 병목을 정확히 찍는다.
병목 찾고 나서 적용한 최적화 3가지가 인상적이었다.
문자열 연산: 루프에서 +로 이어붙이면 매번 새 메모리를 할당한다. strings.Builder (Java의 StringBuilder)로 바꾸면 마지막에 한 번만 생성한다.
초기 용량 지정: 슬라이스나 리스트 크기를 미리 알면 초기에 용량을 잡아줘야 한다. 안 그러면 꽉 찰 때마다 2배씩 재할당이 일어난다.
sync.Pool: 자주 쓰는 객체를 풀에서 빌려서 쓰고 반납한다. Java의 커넥션 풀이랑 같은 개념이다.
이것들이 사실 Java에도 다 있는 개념인데, 프로파일링으로 병목 확인한 다음에 적용했다는 점이 중요했다. 최적화는 측정 후에 한다는 원칙이 실제로 어떻게 동작하는지 본 사례였다.
SLA / SLO / SLI — 안정성을 숫자로 관리하기
이 부분이 이번 아티클에서 제일 새로웠다.
SLI (Service Level Indicator): 실제로 측정하는 값. 당근은 P99 응답시간, 에러율, 제공 아이템 수 같은 걸 측정했다.
SLO (Service Level Objective): 내부 목표 수치. “P99는 500ms 이하로 유지한다” 같은 것.
SLA (Service Level Agreement): 외부와 맺는 공식 약속. SLO보다 느슨하게 잡는다. SLO 못 지켰을 때 버퍼가 있어야 하니까.
1
2
SLO (내부 목표): P99 500ms 이하
SLA (외부 약속): P99 1,000ms 이하

기존에는 “장애 났어요 → 고쳤어요”를 반복했다면, 이 체계를 잡고 나서는 “P99가 540ms에서 418ms로 22.6% 개선됐어요”가 됐다.
에러 버짓도 인상적이었다. 월간 가용성 99.9% SLO면 0.1%, 약 43분이 허용 실패량이다. 이 43분을 다 써버리면 이번 달은 새 기능 배포를 멈추고 안정성 작업만 한다. 개발 속도와 안정성을 숫자로 균형 잡는 방식인데, 막연하게 “안정성 중요해”보다 훨씬 실용적이었다.
마무리
아티클 읽으면서 서킷 브레이커가 이론이 아니라 실제 장애 상황에서 어떻게 동작하는지 감이 왔다. SLA/SLO/SLI는 이름만 들어봤는데, 실제로 수치를 어떻게 설정하고 운영하는지 보니까 훨씬 와닿았다.
서킷 브레이커는 우리 프로젝트에서 외부 API 붙일 때 바로 적용해볼 수 있을 것 같다.